Tech | Taming Python's Long Tail: Inside the GC's Stop-the-World Pause
A deep dive into Python garbage collection, latency tails, object lifetimes, and stop-the-world performance behavior.
Listen
Listen on available platforms
Episode text
Transcript
Overview
Python runtime behavior, garbage collection, latency tails, object lifetimes, and performance traps.
Transcript
Coda: Okay, let’s unpack this. We use high-level programming languages, you know, like Python, because fundamentally we just don’t want to worry about memory.
Odyssey: Exactly. We want the computer, the interpreter to handle all that stuff, the allocation, the delocation, keeping track of it all.
Coda: Yeah, it’s a beautiful abstraction. It lets us focus on the actual problem we’re solving. It absolutely is. It’s the ultimate convenience, really. But, and this is the big but, that convenience comes with a hidden cost, like a hidden clock ticking away.
Odyssey: Yeah, right. And when you start scaling Python, I mean, really scaling it, think millions of requests a day, high-throughput web services, where latency really matters.
Coda: Yeah, where every millisecond counts.
Odyssey: Precisely. That’s when that hidden memory management process, the garbage collector, or GC, suddenly stops being quite so helpful. It turns on you.
Coda: It can feel like it. It starts seemingly randomly pausing your entire application. And not just for a blip, sometimes for seconds at a time. Seconds. In a web service, that’s an eternity. That’s the paradox, isn’t it?
Odyssey: You use Python for speed of development, but then hit these performance walls at scale.
Coda: That’s exactly it. That’s why your median latency, your P50, might look amazing, lightning fast even, but then you look at the P99. The long tail. The 1% of requests that take forever.
Odyssey: Yeah, and that P99 gets completely ruined by these pauses. So our mission today in this deep dive is to basically explore CPython’s subterranean world of memory.
Coda: Okay, let’s do it. We’re going to demystify how CPython actually cleans up its memory. There are really two main parts to it.
Odyssey: Yeah. Reference counting, which most people know about, and then this other thing, cyclic generational garbage collection. And we need to understand why. Why does it cause these multi-second, stop-the-world pauses right in the middle of production?
Coda: Right. And crucially, we’re not just going to talk about the problem. We’re going to look at the solutions. The hard-won engineering fixes that big companies, like, you know, Instagram, Meta, Rippling, close how they actually tamed this beast. So we’ve got some good sources for this real-world stuff. Oh, yeah. We’ve pulled together insights from the core Python documentation itself, a really foundational PyCon talk that actually led to new features in Python and a bunch of recent engineering blogs from these companies.
Odyssey: So practical stuff. Very practical.
Coda: Yeah. They showed the tuning methods, the code changes, the strategies that fixed real performance bottlenecks for them. We’re essentially giving you the shortcut to knowledge that probably cost these places years and, frankly, a lot of money to figure out. Awesome. We’re going right into the trenches then. Runtime optimization. But, okay, to really get the fixes, we first have to understand the problem, right, deeply. Couldn’t agree more. So let’s start right at the beginning. First principles. How does Python actually clean up its own mess?
Odyssey: Okay. So for listeners who maybe come from other managed languages like Java or maybe Go, they’re probably familiar with tracing garbage collection.
Coda: Right. That’s a common model. But CPython, the main Python implementation, it does things a bit differently. It’s more of a hybrid approach. If you ask a typical Python dev how memory works, what do they usually say? They’ll almost always say reference counting. And, well, they’re not wrong. But it’s not the whole story.
Odyssey: Exactly. It’s the immediate cleanup process, the first line of defense, you could say.
Coda: But there’s more going on under the hood. So let’s break down reference counting or RC first. What is it fundamentally?
Odyssey: Okay. So reference counting, RC, it’s really key to how CPython feels and performs. Every single object in Python, whether it’s a simple integer, a list, a string, or even your own custom class instance. Everything. Pretty much everything that’s an object. It carries an internal counter. Think of it like a little integer attached to the object hidden away. That’s its reference count. And what makes that counter go up or down?
Coda: Simple. Every time something creates a new reference to that object, like assigning it to a variable or putting it inside a list or a dictionary, that counter gets incremented. Plus one.
Odyssey: Okay. And conversely, when a reference disappears, maybe the variable goes out of scope or you explicitly use del or an object containing it gets deleted, the counter gets decremented. Minus one. Makes sense. So what happens when that counter reaches zero?
Coda: That’s the magic of RC. When the count hits zero, it means nothing in the program is pointing to that object anymore. It’s inaccessible. So it can be removed. Immediately. The moment it hits zero, CPython deallocates the object. Poof. The memory it was using is instantly freed up and typically returned to CPython’s internal memory pools, these things called arenas. And why is that immediacy so good for Python? What’s the appeal?
Odyssey: Two main things. It’s incredibly fast for this deallocation step, and crucially, it’s deterministic and localized. Deterministic meaning. Meaning you know exactly when the cleanup happens. It happens the instant the last reference goes away. There’s no unpredictable pause later on. And localized means the cleanup happens right where the object became unused. So no waiting for some big global cleanup event.
Coda: Exactly. This prevents memory from building up unnecessarily. It reduces pressure on the OS memory manager. And it contributes to Python feeling very responsive, very immediate. You drop a reference, the memory is gone.
Odyssey: Okay, that sounds pretty great. Fast, immediate, deterministic, effective. So, why isn’t that enough? If RC is so good, why did the Python core devs feel the need to add a whole second system?
Coda: A much slower stop-the-world system. Ah, yeah. There’s one specific situation where RC completely breaks down.
Odyssey: Which is?
Coda: It fails when you have a closed loop of references, what we call a cyclic reference.
Odyssey: Okay, like what? Give us a simple example. The classic one is object A has a reference to object B, and object B simultaneously has a reference back to object A. Like A, B, and B, A, A, A.
Coda: Exactly like that. Or maybe they refer to each other indirectly through a chain. Now, imagine you have some external variable, say Maya, pointing to A. Got it. The reference count for A might be 2, 1 from Maya, 1 from B. And the count for B might be 1 from A. Now, what happens if you delete Maya or it goes out of scope?
Odyssey: Well, the count for A should drop by 1, so it becomes 1.
Coda: Right. But A still has a count of 1 because B is pointing to it. And B still has a count of 1 because A is pointing to it. Ah. So neither count ever drops to 0, even though we can’t access A or B anymore because Maya is gone.
Odyssey: Precisely. They’re trapped. They’re keeping each other alive artificially. From the program’s perspective, they’re garbage, unreachable memory. But reference counting alone can never collect them. They become a memory leak.
Coda: Okay. That’s the crack in the system. And that’s where the second mechanism comes in.
Odyssey: That’s exactly where the cyclic garbage collector, the GC, becomes, well, a necessary evil. It’s a supplemental system designed specifically to find and break these reference cycles. How does it work differently from RC?
Coda: Unlike RC, which is happening constantly with every increment and decrement, the cyclic GC runs only periodically. Its job is to hunt down these groups of objects that have non-zero reference counts but are still somehow unreachable from the main program. Unreachable from where? How does it know what’s reachable?
Odyssey: It starts from what we call the root set. These are all the objects the interpreter knows are definitely alive and accessible. Things like global variables, the objects currently on the function call stack, marginal dictionaries, that sort of thing.
Coda: Okay. The known starting points.
Odyssey: Right. The GC performs a graph traversal starting from this root set and marking every object it can reach by following references. So it follows all the pointers.
Coda: Exactly.
Odyssey: Yeah. Anything it can touch is marked as reachable. Now, after this traversal, it looks at all the objects it knows about. If an object has a non-zero reference count but it wasn’t marked as reachable during that traversal. It must be part of one of those isolated cycles. Bingo. It’s alive according to RC but unreachable from the program’s core. That means it’s garbage, part of a cycle, and the cyclic GC can now safely collect it.
Coda: Okay. Finding cycles sounds complicated. And this is where we hit the performance nag, the painful part.
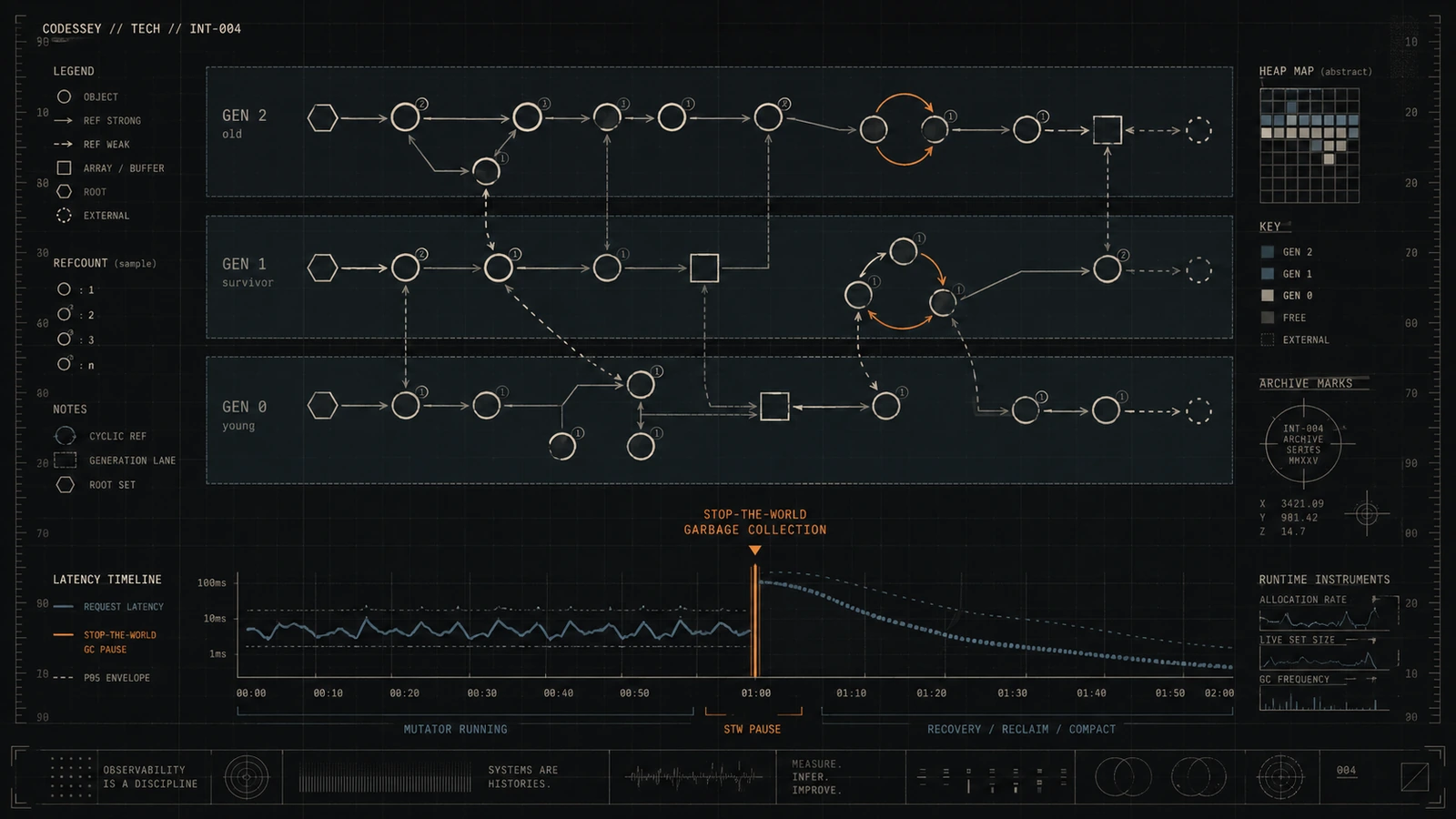
Odyssey: This is it. To do this traversal and marking process safely, the entire Python execution environment has to, well, freeze. Halt completely. The infamous stop the world pause. Why is that necessary? Can’t it just look around while things are running?
Coda: It’s too risky. Imagine the GC is halfway through traversing a complex data structure, like a big dictionary or list. If another part of your Python program, writing concurrently perhaps, modifies that structure, adds an item, removes an item, changes a reference, while the GC is looking at it. Things could get messy. Catastrophically messy. You could end up with memory corruption, dangling pointers, or just as bad, the GC might incorrectly decide an object is garbage when it’s actually still needed, or vice versa.
Odyssey: So stopping the world is the only way to guarantee consistency during the scan. It’s the safe way, yes. All interpreter threads have to be suspended. And for Python, this is a really heavy price. Because that pause, especially for complex cleanups, can last way longer than you’d want. Sometimes longer than it takes to run a high-performance database query. Ouch. Okay, so we have this potentially long pause. But CPython tries to be smart about it, right? It uses this idea of generations.
Coda: Yes, exactly. Knowing that the full cycle GC scan can be expensive, CPython implements an optimization strategy borrowed from the trace in GC world, generational garbage collection. How does dividing objects into generations help? What’s the theory?
Odyssey: It’s based on a common observation in programming, sometimes called the weak generational hypothesis.
Coda: Okay. It basically states that most objects either die very young, they’re created, used briefly, and then become garbage almost immediately, or they tend to live for a very long time, potentially for the entire lifetime of the application. So things are either temporary or practically permanent. Largely, yes. The generational GC exploits this. It divides objects into three distinct generations, numbered 0, 1, and 2. 0 being the youngest.
Odyssey: Precisely. Every new object created in your program starts its life in Generation 0. Now, periodically, the GC performs a collection specifically on Generation 0.
Coda: Okay, it stands the newbies.
Odyssey: Right. If an object in Genero survives that collection, meaning it’s still reachable, gets promoted, it moves up to Generation 1. It graduates. Kind of, yeah. Then, less frequently, the GC does a collection on Generation 1. Any Gen 1 objects that survive that collection get promoted again, up to Generation 2, which is the oldest generation. And Gen 2 gets collected even less often. Much less often. That’s the core optimization. The idea is, don’t waste precious CPU time repeatedly scanning objects that have already proven they’re likely to stick around for a long time, like global configuration, caches, module-level objects.
Coda: Focus the effort on the young objects, because they’re the most likely to be garbage anyway.
Odyssey: Exactly. Scan Gen 0 frequently, Gen 1 less frequently, and Gen 2, the oldest and often largest generation, only rarely. This saves a lot of computation compared to scanning everything every single time.
Coda: Okay, that makes intuitive sense. So how does CPython decide when to actually run these collections for each generation? It’s not just random, is it?
Odyssey: No, it’s based on thresholds. These are really important tuning parameters, as we’ll see later. The GC is triggered based on the number of object allocations minus the number of object deallocations handled by reference counting. It’s a net count. So it tracks how many new objects are sticking around after RC does its immediate cleanup. Correct. Let’s look at the typical default thresholds. You can see these in the GC module documentation. Often there’s something like 700, 10, 10.
Coda: 700, 10. Okay, what do those three numbers mean specifically?
Odyssey: The first number, 700, is threshold 0. This means that after there have been 700 more allocations than deallocations since the last Gen 0 check, a Gen 0 collection is triggered.
Coda: Okay, collect the young ones after 700 net new objects appear.
Odyssey: Right. Now, the second number, 10, is threshold 1. This relates to the previous number. A Gen 1 collection is triggered only when the number of Gen 0 collections since the last Gen 1 collection reaches 10. So after 10 Gen 0 runs, we check Gen 1. Ah, so Gen 1 runs are much less frequent. 10 times less frequent, by default. And the third number, also 10, is threshold 2. Similarly, a Gen 2 collection, the full, most expensive one, is triggered only when the number of Gen 1 collections since the last Gen 2 collection reaches 10.
Coda: So Gen 2 only runs after 10 Gen 1 collections, which themselves only run after 10 Gen 0 collections. That means a full Gen 2 collection happens only after, what, 100 Gen 0 collections by default?
Odyssey: Approximately, yes. It’s designed so that the really deep, potentially slow Gen 2 collection happens quite infrequently under normal circumstances. It only gets triggered if objects consistently survive long enough to get promoted all the way up. And that Gen 2 collection, that’s the big one we need to worry about for latency.
Coda: That’s usually the main culprit, yes. It’s the most computationally intensive. And interestingly, looking at the source code details, during a full Gen 2 collection, gc.collect2 is the explicit call, CPython does extra cleanup. For instance, it clears out its internal free lists for built-in types like floats or tuples. Free lists? What are those?
Odyssey: They’re like little caches the interpreter keeps. Instead of asking the operating system for memory every time you create a float, CPython might keep a list of recently deceased float objects ready to be reused. It’s an efficiency thing.
Coda: Okay. Clearing those during a Gen 2 collection is a sign that the interpreter is really doing a deep clean, trying to reclaim as much memory as possible. But it also adds to the work, and thus adds to that stop-the-world pause time. Got it. So understanding this Gen 2 mechanism, its infrequency but its potential cost, that seems absolutely critical if you’re running a long-lived web server and seeing weird latency spikes.
Odyssey: It is the absolute key.
Coda: Okay, so we’ve established that the Gen 2 collection is this heavy hammer that CPython swings only occasionally, but when it does, it can pause everything. This brings us neatly to the real-world pain points, the kind of problems faced by companies running Python at serious scale. Rippling, the HR and payroll company, had a classic case of this. They called it the long-tail latency problem.
Odyssey: Yeah, their story is really eliminating. They were looking at their monitoring and seeing this massive, worrying inconsistency. Their median API response time, the P50, was great. Super snappy, like 50 milliseconds. Users were generally happy. That sounds perfectly fine.
Coda: It does.
Odyssey: But then they looked further out at the P99 latency.
Coda: That’s the slowest 1% of requests. And those weren’t just a bit slower. They were consistently hitting 3, sometimes even 4 seconds. Whoa, from 50 milliseconds to 3 or 4 seconds.
Odyssey: That’s not a tail.
Coda: That’s a cliff.
Odyssey: Exactly. It’s a huge red flag in web performance engineering. A discrepancy that large usually points to some kind of intermittent, system-wide bottleneck. And the impact wasn’t just theoretical, right?
Coda: It directly affected their users because their front-end application was quite complex. Very complex. A single page load in their app didn’t just make one API call. Sometimes it needed to make up to 30 different API calls concurrently just to fetch all the data needed to render the page. 30 calls per page.
Odyssey: Okay, now I see how that P99 becomes a killer.
Coda: Absolutely. It’s pure statistics at that point.
Odyssey: Yeah. Let’s say, optimistically, only 1% of your individual API calls are slow, hitting that 3-second pause. So 99% are fast.
Coda: Okay. What’s the probability that all 30 calls needed for a single page load will be fast?
Odyssey: You multiply the probabilities.
Coda: Yeah. 0.99 multiplied by itself 30 times. So 0.99 to the power of 30, that’s going to be significantly less than 99%. Way less. Rippling calculated it. It’s about 74%. Only 74% chance of a fast page load. That means roughly one in every four page loads was guaranteed to hit one of those awful three-second delays.
Odyssey: Exactly. One out of four users gets a sluggish, seemingly broken experience.
Coda: That’s completely unacceptable for application stability and user trust. So when engineers see that kind of latency pattern, where do they usually look first?
Odyssey: Database, network, slow external services.
Coda: That’s the standard playbook. Check for slow database queries. Check network latency between services. Look for timeouts talking to third parties. But rippling look. And all those things seemed fine in their logs and monitoring. The database was fast. The network was reliable. They were chasing ghosts, weren’t they?
Odyssey: Pretty much. The problem wasn’t a consistent bottleneck that would show up clearly. It was this random momentary global halt. Something that just froze the entire worker process for a few seconds and then let it continue as if nothing happened. And there aren’t many things that can do that inside a running process without an obvious external cause. Very few. They started to suspect the runtime itself, the Python interpreter. And the prime suspect became the garbage collector.
Coda: But honestly, there’s often reluctance to believe it. Could Python GC really stop the world for multiple seconds?
Odyssey: It sounds extreme. So, suspicion isn’t proof. They needed data. Instrumentation became the key, right?
Coda: How did they actually measure it?
Odyssey: How did they prove GC was the culprit and find out exactly how long these pauses were?
Coda: They used a really neat and actually quite simple API that CPython provides specifically for this. GC.callbacks. Callbacks. Like hooks into the GC process.
Odyssey: Exactly. This API lets you register your own Python functions that the interpreter promises to call at very specific moments during a garbage collection cycle. The most useful ones are the start and stop phases. So you can run code just before GC starts and just after it finishes.
Coda: Precisely. You register a function for the start event. Inside that function, you grab a high-resolution timestamp. Then you register another function for the stop event. Inside that function, you grab another timestamp and calculate the difference. Ah, that gives you the exact duration of the pause. The time the world was stopped. Undeniable proof. And crucially, the information passed to these callbacks also includes which generation was being collected 0, 1, or 2.
Odyssey: So they could see if it was the quick Gen O scans or the big Gen 2 ones causing the long pauses.
Coda: Exactly.
Odyssey: So they rolled out this instrumentation across their fleet of web workers. And the results. What did the data show?
Coda: It confirmed their worst fears, unfortunately. The data clearly showed worker processes pausing, completely frozen, for typically 2 to 4 seconds. And these long pauses correlated perfectly with collections of the third generation Gen 2. Wow.
Odyssey: So the smoking gun was found. And they weren’t the only ones seeing this, right?
Coda: You mentioned Close as well.
Odyssey: Right. Close, another company building a large Python application, ran into similar weird latency issues. They used different debugging tools but found the same pattern. Random pauses. Maybe shorter in their case, like 150 to 200 milliseconds. But happening frequently, maybe every dozen requests or so. Still significant enough to mess up your P95 or P99 targets if they happen often. Definitely. It just destroys the consistency of your service.
Coda: Okay.
Odyssey: So the diagnosis points squarely at Gen 2 collections.
Coda: But the big question is still why. Why would scanning Gen 2 take seconds?
Odyssey: Isn’t it just traversing objects and marking them?
Coda: How can that be so slow?
Odyssey: This gets to the core in efficiency, especially in the context of long-running server processes like web workers or background job processors. Think about how these applications typically start up.
Coda: Okay. They load a ton of code, right?
Odyssey: Import hundreds of modules.
Coda: Exactly. They import frameworks like Django or Flask. All their own application code libraries. They set up potentially massive internal data structures, configuration objects, maybe caches loaded from disk or a database. They initialize database connection pools, thread pools. A whole lot of setup happens before the server even processes its first request. A huge amount.
Odyssey: Yeah. And all those objects created during this startup phase, the module dictionaries, the class definitions, the function objects, the big config dictionaries, the cache data. What’s their life cycle?
Coda: Well, they need to stick around for the entire life of the process, basically hours, maybe days.
Odyssey: Right. They’re inherently long-lived.
Coda: So what happens when the GC runs its initial collections shortly after startup?
Odyssey: They survive Gen 0, survive Gen 1, and get promoted straight into Gen 2. Bingo. All this static essential application infrastructure ends up residing in Generation 2. It often accounts for hundreds of megabytes of memory, maybe even gigabytes in very large applications.
Coda: Okay. So Gen 2 becomes full of these permanent static objects. And here’s the kicker. The cyclic GC algorithm, by default, doesn’t know they’re static or permanent. Every single time a Gen 2 collection is triggered, even if it’s infrequent, the GC has the obligation to traverse this entire graph of potentially hundreds of megabytes or gigabytes of objects. Just to check if they’re still reachable. Yes. It has to start from the root set and meticulously follow every reference to mark every single one of those long-lived global static objects as still reachable.
Odyssey: Even though we, the developers, know perfectly well they’re never going to be collected because they’re essential parts of the running application.
Coda: Exactly. It’s pure wasted CPU time during that critical stop-the-world pause. The GC spends potentially seconds just confirming that the giant dictionary holding your application configuration, which was loaded three hours ago and hasn’t changed, is still reachable. Of course it is. It’s scanning massive, effectively immutable structures just because they happen to live in Gen 2, and the GC algorithm is designed to be thorough. It’s the definition of computational busywork during the worst possible time when your application is frozen.
Odyssey: The GC algorithm assumes, quite conservatively, that any object in Gen 2 might theoretically be part of some complex, unreachable cycle that needs cleaning up, so it has to check them all. And this pattern server process is doing extensive setup, creating a large, long-lived Gen 2 population that’s common, isn’t it?
Coda: Extremely common. It’s almost the standard way monolithic web applications are built.
Odyssey: And that’s precisely why so many different companies like Rippling and Close independently discovered these multi-second latency spikes caused by Gen 2 GC. It’s a merchant property of the architecture and the default GC behavior. Wow. Okay, so that inefficiency of scanning static objects in Gen 2 is already bad enough just from a pure CPU waste and latency perspective.
Coda: That’s pretty bad, yeah. But it gets even worse, doesn’t it?
Odyssey: When you combine Python’s GC with certain operating system optimizations that are crucial for scaling, the GC doesn’t just waste CPU cycles, it actively starts sabotaging memory efficiency. Oh, absolutely. This brings us to a really fascinating, almost legendary engineering story, the copy-on-write crisis faced by Instagram, which is now part of Meta.
Coda: Right. This story actually led to changes in Python itself, didn’t it?
Odyssey: It did. It’s a fantastic case study and unintended consequences at scale. So Instagram’s backend, running massive amounts of Python with Django, used a common web server architecture, a multi-processing model with UWSGI. Crucially, they relied on pre-forking worker processes from a master process. Pre-forking. Let’s break that down. The idea is to load the application once in a master process.
Coda: Right. Do all that expensive setup, import everything, initialize stuff. And then, before accepting any requests, the master process uses the fork system call to create multiple child worker processes.
Odyssey: Exactly. And the magic here relies entirely on a brilliant Linux kernel feature called copy-on-write, or coww.
Coda: Okay. Let’s nail down coww for everyone. Why is it so important for memory saving in this forking model?
Odyssey: When that fork happens, the OS does something really clever. Instead of immediately duplicating all the memory used by the master process for each child, which could be hundreds of megabytes or more, and very slow.
Coda: Yeah, that would defeat the purpose.
Odyssey: Totally. Instead, the kernel just sets up the child process’s virtual memory tables to point to the exact same physical memory pages that the parent process is using. So, parent and child initially share all the physical RAM. Instantly. Instantly and efficiently. They share the Python interpreter’s code, all the loaded libraries, all the static data structures created during startup. But there’s a catch. These shared pages are initially marked as read-only by the kernel.
Coda: Read-only. Okay. So, what happens if one of the processes tries to write to a shared page?
Odyssey: That’s the copy-on-write part. The moment either the parent or, more commonly, one of the child workers attempts to modify even a single byte on one of these shared memory pages, it triggers a hardware protection fault. The kernel catches this fault. And then?
Coda: And then the kernel quickly, transparently, makes a private copy of just that specific 4-kilobyte page for the process that tried to write. The write operation then completes on the private copy. The other processes continue sharing the original page untouched. Ah. So, you only pay the memory cost, a new 4-kb page, for the specific pages that actually get modified. Everything else remains shared. That’s a huge win for memory density. It’s essential for running lots of Python workers efficiently on one machine. You load the big framework once, and dozens of workers share most of that memory footprint.
Odyssey: Okay. Brilliant optimization. Enter the Python garbage collector. How does the GC manage to mess this up?
Coda: This is where Instagram’s engineers noticed something deeply wrong. They were monitoring their server memory usage, specifically the amount of shared memory between the master and the child processes after forking. And they saw that shared memory size drop. Sharply.
Odyssey: Right after a child worker processed its very first web request. We’re talking a drop from maybe 500 millibytes of shared memory down to 350 millibytes per process. Wait, 150 megabytes of memory suddenly became unshared and duplicated just because the worker handled one request. That’s insane. It was massive waste. Across their whole fleet, it added up incredibly quickly. They needed to figure out what was causing all these pages to be copied.
Coda: So they profiled it, looked for the source of the page faults. They did. They used low-level system tracing tools. And the data was shocking, frankly. About 20 percent, one-fifth of all the page fault events, the moments the OS had to stop and copy memory, were directly caused by one specific function call in the child process. GC.collect. The garbage collector itself was triggering the copy on write. But how? Isn’t GC mostly about reading object references and maybe freeing memory? How does it write to shared pages?
Odyssey: This requires diving deep into the internal structure of CPython objects. We mentioned the reference count earlier. That’s stored in the object’s header.
Coda: But the header also contains other internal metadata bits, things the cyclic GC uses during its traversal phase. Engineers sometimes call this the GC hat or GC flags. These are bits that mark the object’s state during collection. Is this object reachable? Have I visited this object yet? Which generation does this belong to?
Odyssey: Tiny little bookkeeping flags inside the object’s structure itself.
Coda: Exactly. Now, when the cyclic GC runs its collection cycle, part of its algorithm involves modifying these flags on the objects it encounters as it traverses the graph. It needs to mark them. Uh-oh. I think I see where this is going.
Odyssey: Yep. Remember all those large, static, long-lived objects created during startup? The ones living in Gen 2?
Coda: The ones sitting in memory pages shared between the master and child thanks to count W.
Odyssey: Precisely. Now, imagine the GC runs in a child process after the fork. It starts traversing the object graph, including these shared static objects, when it needs to flip one of those internal GC flag bits on an object residing in a shared memory page. That counts as a write operation to that page. Bingo. Even changing just one single bit is a modification. And that modification attempt immediately triggers the copy-on-write mechanism. The kernel intercepts makes a private 4KB copy of the entire page for that child process just so the GC can flip its little bookkeeping bit.
Coda: Oh, that’s brutal. The GC, simply by doing its standard bookkeeping, was systematically destroying the memory sharing provided by COW for all those static objects. It was a fundamental conflict between the GC algorithm’s need to modify object metadata and the operating system’s COW mechanism designed for sharing immutable data. The GC was forced, by its design, to make copies of memory that should have ideally remained shared forever.
Odyssey: Okay. Faced with that level of inefficiency, 150 mb wasted per process on the first request, the Instagram meta-engineers must have considered some pretty radical solutions. What was the first most drastic thing they tried?
Coda: They went for the nuclear option first. They completely disabled the cyclic garbage collector. Just turned it off. By setting the collection thresholds to zero, GC.threshold, zero, zero, zero, this effectively tells the GC, never run a collection for any generation based on allocation counts. It prevents the periodic cyclic GC from ever kicking in. Wow. Okay. Did that actually work? What happened?
Odyssey: The immediate results were stunningly good, actually. Really?
Coda: Yeah. Shared memory utilization instantly jumped up by about 100 megabytes per worker process because the GC wasn’t triggering COW anymore. Their overall server memory footprint dropped by about 15%. And, maybe even more importantly, their CPU throughput, measured as instructions per cycle, IPC, increased by 10%. 10% more CPU efficiency. Why would disabling GC improve CPU throughput?
Odyssey: Less cache pollution, likely. The GC’s traversal touches a lot of memory, potentially evicting useful application data or instructions from the CPU caches. By stopping the GC, they kept the caches hotter with application logic, leading to better IPC. So, yeah, it looked like a massive win initially. Sounds brilliant, except we already established why the cyclic GC exists in the first place, right?
Coda: Exactly. Disabling it comes with an unavoidable ticking time bomb. Memory leaks from cyclic references. The problem RC can’t solve. The very problem. And sure enough, while Python programs might not create obvious cycles constantly in large, complex code bases using frameworks like Django, subtle cycles do get created over time. Things held in request caches, ORM object relationships, maybe complex data structures. So, without the cyclic GC running as a backup. Those cycles just piled up, slowly but relentlessly.
Odyssey: Instagram ran this experiment for about a year, and the results were clear. Their worker processes started leaking memories significantly. After handling only about 3,000 requests, a typical worker might have leaked up to 600 megabytes of unreachable, cyclically referenced garbage. 600 megs? That’s huge!
Coda: So they’d just run out of memory eventually?
Odyssey: They would. The only way to manage it was to aggressively kill and restart the worker processes much more frequently, just to reclaim that leaked memory. Ah, but restarting workers isn’t free either. There’s startup time, cash warming.
Coda: Exactly. The operational overhead and capacity loss from these frequent restarts started to completely negate the memory and CPU gains they’d achieved by disabling GC in the first place. They were stuck. They needed the GC to prevent leaks, but they couldn’t afford the COW penalty it imposed. A classic engineering dilemma. They needed a way to have their cake and eat it too. And this pressure, this specific problem, is what directly led to a new feature being added to CPython itself.
Odyssey: Precisely. This whole saga was the primary motivation for the GC.freeze API, which landed in Python 3.7. Freeze?
Coda: Okay, what does GC.freeze do?
Odyssey: How did it solve their dilemma?
Coda: The core idea was elegant. If the problem is that the GC touches the metadata of long-lived static objects after the fork, causing COW, well, what if we could just tell the GC to ignore those specific objects entirely?
Odyssey: Hide them from its view before the fork happens?
Coda: Move them somewhere the GC won’t look?
Odyssey: Essentially, yes. The GC.freeze function does something clever. It takes all the objects that are currently being tracked by the GC, specifically those that have already survived collections and are residing in the older generations, mostly Gen 2 in practice, and moves them into a special conceptual permanent generation. A permanent generation, like Gen 3. You can think of it that way, though it’s not technically a numbered generation, like 0, 1, 2. It’s more like a separate list of objects that the GC is told to permanently ignore during its regular collection cycles.
Coda: So, once an object is frozen, the cyclic GC will never scan it, never traverse it, never touch its GC metadata bits again?
Odyssey: Exactly. It’s effectively removed from consideration for all future cyclic collections. The object still exists, it still takes up memory, you can still use it, but the GC simply pretends it’s not there when doing its cycle detection runs. Ah, and how does that help with COW?
Coda: The timing is critical. The idea is to freeze the objects before the fork happens. All those big, static, shared objects created at a startup get frozen in the master process. Then, when the child process is forked, it inherits these objects already marked as frozen.
Odyssey: So the child’s GC, when it eventually runs?
Coda: It completely ignores those frozen, shared objects. It never touches their metadata, so it never triggers the copy-on-write page faults for that shared startup state. Brilliant. But wait, what about cycles created after the fork?
Odyssey: Like during request processing in the child, don’t those still need collecting?
Coda: Yes, absolutely.
Odyssey: And that’s the other crucial part of the strategy. Freezing only affects the objects that exist at the time GC.freeze is called. Any new objects created by the child process while handling requests are tracked normally by the GC in generations 0, 1, and 2.
Coda: So the child’s GC can still run and collect any new cycles generated during its own lifetime without messing with the frozen, shared stuff.
Odyssey: Precisely. You get the best of both worlds. Prevent the CalW disaster on the shared startup memory, but still allow the GC to clean up new garbage generated by request handling, thus preventing the memory leaks.
Coda: Okay, so the final optimized workflow developed by Instagram meta looks like what?
Odyssey: A sequence of steps around the fork. It became a carefully choreographed pre-fork dance. The standard pattern, now widely used by large Python deployments relying on CalW, is this. 1. In the master process, before forking, temporarily disable the GC, GC.disable. 2. Run a full explicit collection, GC.collect2, just to make sure the master’s memory space is as clean as possible before freezing. 3. Call GC.freeze. This moves all the existing long-lived objects, the big static stuff, into the permanent ignored generation.
Coda: 4. Now perform the fork operation to create the child worker processes. 5. Finally, in each newly started child process, immediately re-enable the GC. GC.enable. Wow, that’s surgical.
Odyssey: It is. It ensures the child’s GC is active to handle request-specific cycles and prevent leaks, while guaranteeing that the large, shared, static objects inherited from the master remain untouched by the GC, preserving the copy-on-write memory savings. It perfectly addressed the root cause of their crisis. That Instagram meta story is really something solving a problem so fundamental it actually changed CPython. But, you know, not everyone runs their Python apps using that specific pre-fork, copy-on-write, maximizing architecture.
Coda: That’s true. Many setups use threading or different process models or maybe run on platforms where CowW isn’t as central.
Odyssey: Right. So companies like Rippling and Close, who we talked about earlier, they were facing the latency problem of Gen 2 collections more directly. Those multi-second pauses in their long-running workers, even without the CowW complication.
Coda: Exactly. Their primary pain point was the sheer time spent paused inside GC.collective, caused by scanning all that static Gen 2 data.
Odyssey: So they took the lessons learned, particularly that scanning static objects is just wasteful, and they developed some different tuning strategies, right?
Coda: Not necessarily requiring GC.freeze just for CowW, but maybe using it or other techniques purely for latency control.
Odyssey: That’s right. They developed or perhaps rediscovered and refined about three key strategies for taming GC latency in typical web server environments.
Coda: Okay, let’s break those down. What’s strategy number one?
Odyssey: Strategy one is basically taking the GC.freeze concept we just discussed, but applying it purely for latency reduction, not necessarily for CowW benefits. So using freeze just to stop the GC from wasting time scanning stuff it knows won’t be collected?
Coda: Precisely. They recognized, just like Instagram did, that the bulk of the time spent in those two to four second Gen 2 pauses was the pointless traversal of hundreds of megabytes of static objects loaded at startup.
Odyssey: So the fix is similar. Freeze them early. Very similar. The implementation is often just a couple of lines of code executed right after the main application initialization is complete, perhaps in the WSGI entry point script or wherever the app finishes its major setup. What code?
Coda: Typically, just GC.collect2, followed immediately by GC.freeze. So run one full cleanup just in case, and then immediately freeze everything that survived, which is presumably all the static startup stuff.
Odyssey: Exactly. This ensures that all those massive global structures, the config objects, the caches, the module data, the things guaranteed to live for the process lifetime, are moved out of the regular GC generations and into the permanent frozen state. They’re simply taken off the list for future Gen 2 scans. And what was the impact on latency for Rippling when they did this?
Coda: Did it fix the multi-second pauses?
Odyssey: It had a huge impact. They reported that their average third generation Gen 2 collection time dropped by over 80%. 80%?
Coda: Yeah. Those crippling multi-second pauses were consistently brought down to under 500 milliseconds. Still a pause, but much, much more manageable.
Odyssey: That’s a massive improvement for P99 stability right there. Basically makes Gen 2 scanning itself a non-issue for latency. Pretty much. By excluding the vast bulk of uncollectible objects from the scan list, they eliminated most of the work the GC was pointlessly doing during those pauses.
Coda: Okay, so freezing helps dramatically reduce the duration of the GC pause by cutting out wasted work. But it doesn’t change the fundamental fact that GC is still a stop-the-world event, right?
Odyssey: Even a 500 meters pause, if it happens right in the middle of handling a user request, is still pretty bad for perceived performance.
Coda: Absolutely. That 500 meters is way better than 4 seconds, but it’s still unacceptable if it hits during a live request. This realization pushed companies like Rippling towards strategy number two, deferred GC. Deferred GC, meaning run the GC, but later.
Odyssey: Exactly. The absolute core goal here was, We acknowledge that cyclic GC must run eventually to prevent memory leaks, but we cannot, under any circumstances, tolerate that stop-the-world pause happening while we’re actively processing a user’s API request. The pause has to be shifted to a time when the application is effectively idle.
Coda: Okay, but how do you guarantee that?
Odyssey: Web servers are complex beasts. A request might look finished from the application code’s perspective, but the server might still be streaming response data back to the client over the network, or cleaning up resources. How did Rippling make sure the pause happened only when the process was truly doing nothing critical?
Coda: They got quite clever by leveraging the architecture of their web server, which was Gunicorn in their case. Gunicorn is written in Python and is quite extensible. It allows you to provide custom worker classes. Ah, so they could hook into Gunicorn’s request lifecycle?
Odyssey: Precisely. Rippling implemented their own specialized Gunicorn worker class, which they called Deferred GC Sync Worker. What this custom worker essentially did was wrap the main application request handling logic. How did it wrap it?
Coda: It put the call to the actual WSGI application, the part that handles the request, inside a try, not finally block. And crucially, the call to GC that collect was placed inside the finally part. Finally. Okay, why is that significant here?
Odyssey: Because in Python, the code in a finally block is guaranteed to execute after the code in the try block finishes, regardless of whether the try block completed successfully or raised an exception.
Coda: Right. In the context of a WSGI request handler, the try block contains the code that generates the response. Once that function returns, the finally block executes. By putting GC.collect there, Rippling ensured the potentially long GC pause would only begin after the main application logic for the request was totally finished, the response headers and status were likely sent, and the server was potentially just finishing streaming the body or closing the connection. Ah, so the user likely already received their fast 50 meters response, and then the server took its 500 meters GC pause completely offline from the user’s perspective before picking up the next request.
Odyssey: That’s exactly the idea. Surgically move the unavoidable pause out of the critical path of user-facing latency. The cleanup happens, but it happens in the gaps between requests.
Coda: That is incredibly precise tuning. Did they just run GC.collect after every single request?
Odyssey: Wouldn’t that be too frequent?
Coda: Good point. No, they paired this deferral mechanism with a smart schedule. They didn’t want the deferred GC pause to become huge because they waited too long and accumulated tons of garbage.
Odyssey: Right. You’d trade frequent small pauses for infrequent giant pauses.
Coda: Exactly. So they used a simple interval-based schedule. They decided to run the expensive deferred Gen 2 collection only once every, say, 50 requests. And they’d run a deferred Gen 1 collection maybe every 10 requests. Gen 0 they might let run more normally or also defer lightly.
Odyssey: So they staggered the collections, ensuring the deferred pauses stayed relatively small while still preventing leaks over time. Correct. Keep the memory tone manageable. Defer the collection work to non-critical times. And this combined strategy deferral plus scheduling gave them another significant win. They reported a further 40% reduction in their P99 latency on top of the gains from freezing. Very impressive. Okay, that covers freezing and deferral. What’s strategy number three?
Coda: You mentioned close focused on tuning the collection frequency itself. Yes. This strategy goes right back to those thresholds we talked about in part one, GC.threshold. Threshold 0, threshold 1, threshold 2. The 700, 10, 10 defaults.
Odyssey: Exactly. Remember, threshold 0 being 700 means a Gen as a collection happens after only 700 net object allocations. For a busy API worker handling thousands of requests per minute, creating and destroying tons of temporary objects for each request. You’re going to hit 700 net allocations constantly. All the time. All the time. Which means the cyclic GC, even just for Gen 0, is potentially kicking in very frequently, causing tiny but frequent stop-the-world pauses.
Coda: If you’re great if Gen 0 is fast, those frequent tiny pauses add up, especially under high load. They absolutely do. The key insight the engineers at Close had was this. Reference counting is actually really good and really fast at clinging up the vast majority of objects created during a typical web request, because most of them are short-lived and don’t form cycles. Like request context objects, temporary variables, database results that are processed and discarded?
Odyssey: Exactly. RC handles all that beautifully and immediately. So, close-figured, why trigger the expensive, world-stopping cyclic GC so often?
Coda: Why not give reference counting much more breathing room, much more time to do its job, before we even consider running the cyclic collector?
Odyssey: How do you give RC more breathing room? By increasing the thresholds?
Coda: Precisely. Specifically, by dramatically increasing threshold 0.
Odyssey: Okay, but hold on. Isn’t that risky? If you increase threshold 0 from 700 to, say, tens of thousands, aren’t you just delaying the inevitable?
Coda: Won’t you eventually accumulate way more garbage, including potentially more complex cycles, making the eventual GC pause much longer and more painful when it finally runs?
Odyssey: That is the exact tradeoff and the potential danger. It’s a fantastic point. If you let garbage pile up for too long, the GC might indeed have a much harder job when it eventually runs, potentially leading to a massive latency spike. So how did Close manage this risk?
Coda: They made a calculated bet. They hypothesized that the vast majority of objects being created were short-lived and would be cleaned up by RC long before the threshold was hit, even if that threshold was much higher. They believed the number of actual cyclic garbage objects being created was relatively low.
Odyssey: So they were betting that increasing the threshold wouldn’t significantly increase the amount of cyclic garbage, just the amount of time RC had to work before the cyclic check happened. Essentially, yes.
Coda: Yeah. They decided to trust RC more, so they experimented. They cranked threshold way up. From the default of 700, they pushed it up to 50,000. 50,000. That sounds almost reckless. It seems like it. But for their workload, it worked wonders. By setting the threshold that high, they allowed thousands upon thousands of requests to be processed, with RC cleaning up the vast majority of temporary garbage immediately without ever triggering a single cyclic GC run.
Odyssey: They dramatically reduced the frequency of the Stop the World events. Massively. The number of times the cyclic collector had to run just plummeted. They monitored their overall GC CPU utilization, the percentage of total CPU time spent inside garbage collection routines. It dropped from around 3% of total runtime down to about 0.5%. Wow. That’s a huge reduction in overhead. And what did it do for their user-facing latency?
Coda: The payoff was very real there, too. They saw their P95 latency, the 95th percentile, improved by a solid 80 to 100 milliseconds, just by telling the cyclic GC to run much, much less often. Incredible. So these three strategies, freezing static objects, deferring GC pauses, and tuning thresholds way up, they really show that for serious Python services, you can’t just accept the defaults.
Odyssey: Absolutely not. The defaults are a reasonable starting point for general scripting, but for high-performance, latency-sensitive, long-running applications, they’re often far from optimal. Manual, informed tuning based on understanding these mechanisms and using instrumentation is pretty much a prerequisite for stability.
Coda: It really proves you can take control. You instrument to find the problem, usually Gen 2 scanning waste. You use freeze to eliminate that waste. You use deferral to hide the remaining necessary pause. And you tune thresholds to dramatically reduce how often the pause even needs to happen, letting RC do the heavy lifting. You summarize it perfectly.
Odyssey: That’s the playbook developed by these companies to make Python perform consistently under pressure.
Coda: So the stories we’ve covered show engineers really wrestling with the CPython runtime, using clever wrappers like DeferGC or APIs like Freeze to kind of work around the default GC behaviors from the outside.
Odyssey: Right. They’re applying fixes at the application level.
Coda: But the big lesson, especially from that meta Instagram CowW story, the fundamental problem of touching shared memory that seems to be driving even deeper changes now, right?
Odyssey: Changes happening inside the CPython core itself. Yes, absolutely. The learnings from these large-scale deployments are feeding back into the evolution of CPython. And a prime example of this landed in Python 3.12, the concept of immortal objects. Immortal objects? Sounds dramatic. What are they technically?
Coda: Technically, they’re formalized in PP683. An immortal object is a Python object that is explicitly marked in a way that guarantees it will live until the entire interpreter shuts down. And crucially, the key feature is that they are designed not to participate in reference counting. No reference counting. But isn’t reference counting fundamental to CPython?
Odyssey: How can an object exist without it?
Coda: This is why it’s such a potentially revolutionary change to the object model. Remember, every standard CPython object header has fields for things like the object’s type pointer and, importantly, its reference count, OBRASENT.
Odyssey: Right. For an immortal object, that OBRASENT field is effectively ignored or repurposed. The implementation details involve using specific bits in the object header, often the bits normally used for GC generation tracking. By setting these bits to a special fixed pattern, the runtime knows. This object is immortal. Its reference count conceptually never changes and will never be garbage collected.
Coda: So the runtime just knows not to touch its reef count or try to GC it.
Odyssey: Exactly. It’s permanently alive, permanently fixed. And the motivation for creating such a thing goes directly back to that Instagram COW problem. Directly. That was the primary driver. Remember, the COW issue is triggered because either the reference count field or the internal GC status flags were being modified on objects living in shared memory pages.
Coda: Right. Causing the page copy. If an object is immortal, its reference count never changes, conceptually, and its GC status flags are fixed to indicate immortally nor. Therefore, if such an object lives in a shared memory page inherited by a child process after a fork, nothing the child process does, no reference creation, no GC scan will ever attempt to write to that object’s header metadata. Ah. So it completely eliminates the COW trigger at the source just by changing the fundamental nature of the object itself.
Odyssey: Precisely. It allows truly static shared data structures, like parts of the standard library, common types, etc., to live in COW shared memory without ever risking that detrimental page duplication.
Coda: That’s a much more elegant solution than the GC.freeze workaround, although freeze is still useful for application-level objects. But you said the implications go beyond just fixing COW for web servers. Oh, much further. This idea of objects that don’t participate in reference counting is a massive foundational step towards tackling Python’s biggest scalability challenge, the global interpreter lock, or GIL. The GIL.
Odyssey: Okay, connect the dots for us. How do immortal objects help with potentially removing the GIL someday?
Coda: This is the bigger picture, the long-term vision. The GIL exists primarily because many of CPython’s core internal operations and data structures, especially reference counting, but also things like dictionary accesses and memory allocation pools, are not inherently thread-safe. Meaning if two threads tried to modify the same object’s riff count at the same time without the GIL protecting them?
Odyssey: You’d get race conditions, corrupted counts, and likely interpreter crashes. Chaos. The GIL ensures only one thread can execute PyCon bytecode at a time, preventing these races, but also preventing true CPU-bound parallelism on multi-core processors. Now, if you have an object that is immortal, its reference count never needs to be modified. It’s constant. This immediately removes one massive source of contention and thread safety concern for that object. So, immortal objects are inherently safer to access from multiple threads without the GIL.
Coda: Potentially, yes. Especially if they are also immutable, meaning their actual data content can’t change either. If an object is both immortal and immutable, it becomes perfectly safe to share and read concurrently across multiple threads, or even potentially across different sub-interpreters within the same process, without needing any locking. And the efforts around GIL removal, like the experimental work based on PP703, rely heavily on this idea.
Odyssey: Absolutely. The PP703 proposal, which aims to make the GIL optional, involves fundamental changes, like using finer-grain locking in some places, but also relies heavily on making many of CPython’s core built-in objects, LOPJECT, type objects, int, strie, list, code objects, function objects, method wrappers, effectively immortal and immutable. So, the interpreter’s own internal machinery becomes inherently thread-safer.
Coda: Exactly. Immortal objects provide the mechanism to formally mark these core components as permanently safe and read-only, which is a necessary architectural building block for enabling safe, concurrent execution in potential future non-GIL Python. It reduces the number of places where explicit locking is needed.
Odyssey: That’s fascinating. It’s like they’re slowly changing the foundations of the runtime to support parallelism better. Now, besides this huge structural change with immortal objects, Meta has also been contributing other, maybe smaller, performance wins in recent Python versions, like 3.12, that also help indirectly with GC load, right?
Coda: Yes. There’s definitely been a focus on reducing what’s called temporary object churn. Churn. Just the sheer rate at which temporary short-lived objects are created and then immediately destroyed. Remember, every time an object is allocated, RC needs to initialize its count. Every time it’s deallocated, when the count hits zero, work needs to be done. Reducing the number of unnecessary temporary objects saves cycles in RC and also reduces the rate at which the GC allocation thresholds are hit.
Odyssey: Makes sense. Can you give an example from Python 3.12 where this kind of churn was reduced?
Coda: A really good one is PP709, which changed how comprehensions work internally. List comprehensions? Dict comprehensions?
Odyssey: Exactly. In older Python versions, when you executed something like XX for X in range 10, the compiler actually generated code that involved creating a temporary hidden function object to execute the loop body, XX. Really? A whole function object just for that?
Coda: Yeah. So every time you ran the comprehension, CPython would allocate this function object, use it, and then immediately destroy it.
Odyssey: That’s classic object churn. Totally unnecessary overhead. And in 3.12. With 3.12 and PP709, comprehensions are now compiled more directly, often using dedicated bytecode instructions that avoid creating that temporary function object altogether. So it’s faster and creates less garbage.
Coda: Exactly. It’s faster, and importantly, it reduces the workload on the reference counting system. Fewer allocations mean the GC thresholds, like that default 700, are hit less often, delaying the need for the potentially pausing cyclic GC runs. It’s a subtle change. But if your code uses a lot of comprehensions, it could add up significantly, reducing pressure on the whole memory system.
Odyssey: It really does. Another similar example in 3.1 was optimizing supercalls. Previously, calling a method via super.sum method also involved creating a temporary super object instance behind the scenes, which was then immediately thrown away. More churn. More churn. Now, with a new bytecode instruction, load super at tr, that temporary object allocation is often eliminated. Again, faster execution and less pressure on memory management. Every little bit helps push back that expensive cyclic GC run.
Coda: It feels like there’s a concerted effort to make the baseline Python execution just more efficient with memory. There definitely is. And alongside these CPython core changes, Meta also invested heavily in contributing infrastructure they called CinderX hooks. Now, Meta’s own high-performance JIT compiler, Fender, is an open source, but the hooks they added to CPython are… Hooks for what? What do they allow?
Odyssey: They’re essentially APIs designed to help third-party just-in-time compilers, or other runtime analysis tools, work more effectively and safely with Python’s dynamic nature. How so?
Coda: JIT compilers work by making assumptions. They might see a piece of Python code accessing a dictionary and say, OK, I assume the structure of this dictionary won’t change, so I can compile this access into superfast machine code. But Python is dynamic. Someone could change that dictionary later.
Odyssey: Right, breaking the JIT’s assumption.
Coda: Exactly. The CinderX hooks provide mechanisms called watchers, like dictionary watchers, type watchers, function watchers. The JIT can register a watcher on an object. If that object gets modified dynamically later on in a way that violates the JIT’s assumptions, the watcher mechanism notifies the JIT.
Odyssey: So the JIT can then invalidate its optimized machine code and safely fall back to the slower standard interpreter path.
Coda: Precisely. It allows JITs to be aggressively optimistic, but still correct in the face of Python’s dynamism. And while that’s not directly memory management, it ties into that overall theme of making Python’s performance more predictable and robust, right?
Odyssey: Reducing random slowdowns, whether they come from GC pauses or JIT deoptimizations. It absolutely fits the pattern. The goal is to smooth out those performance cliffs, flatten the latency curve, and make Python a reliable platform for even the most demanding, high-scale, low-latency use cases. All these efforts, from GC tuning to immortal objects to JIT hooks, point in that direction. Hashtag tag tag outro. Wow.
Coda: Okay. This deep dive has really taken us on a journey. We started with the simple elegance of reference counting. The thing that makes Python feel so immediate. And then plunged right into the complexities of the cyclic GC, the generational system, and the sometimes brutal stop-the-world pauses it causes.
Odyssey: Yeah, the necessary evil that trips up high-scale applications. And we’ve seen compelling evidence from companies like Instagram, Rippling, and Close that CPython’s default GC settings, while fine for general use, are often a direct cause of instability and terrible P99 latency in high-throughput web APIs.
Coda: Absolutely. I think the main takeaway, the core lesson here, is that if you’re running Python in any kind of long-running, high-concurrency scenario, web servers, job queues, anything sensitive to pauses, you cannot treat the garbage collector as a black box you just ignore. You have to engage with it. You have to understand it, instrument it, and be prepared to tune it. Those multi-second pauses that destroy performance consistency, they aren’t inevitable. They’re almost always solvable with informed action.
Odyssey: And we’ve identified a clear set of strategies, a kind of playbook based on these companies’ experiences. Step one, instrumentation. You absolutely need to use tools like GC.callbacks to prove the GC is the problem and measure exactly how long the pauses are and which generations are causing them. And fix what you can’t measure. Step two, address the biggest source of pause time, the wasted scanning of static objects in Gen 2. Use GC.freeze right after your application initializes to take all that static bulk out of the GC’s regular scans.
Coda: That alone can give you an 80% plus reduction in pause duration.
Odyssey: Right. Then, step three. If even the shorter pause is unacceptable during a request, consider deferring the GC entirely. Use techniques like custom gun-a-corn workers with finally blocks to push the GC.collect. Call into the idle time between requests, making the pause invisible to the user. Surgically hide the latency. And finally, step four. Don’t underestimate the power of tuning the thresholds. As Close demonstrated, dramatically increasing threshold 00, giving reference counting way more room to work, can significantly reduce the frequency of cyclic GC runs, lowering overall GC overhead, and improving latency by letting the faster RC handle more cleanup.
Coda: These are the techniques, freezing, deferral, threshold tuning. They’re not necessarily obvious. They require understanding the internals.
Odyssey: But they are the hard-won, necessary steps for achieving performance stability with Python at scale. They really are. And it’s these kinds of optimizations, often pioneered out of necessity by large engineering orgs pushing Python to its limits, that ultimately allow the language to remain a viable, even excellent choice for building massive, demanding systems. And connecting this back to the bigger picture, like you said, it feels like we’re seeing an acceleration. These low-level runtime optimizations, driven by real-world pain points, are being contributed back into the open-source CPython core.
Coda: Things like immortal objects aren’t just patches, they’re fundamentally changing the language’s object model.
Odyssey: Exactly. It feels like Python is actively evolving its internal architecture to better handle the concurrent latency-sensitive workloads that dominate modern software development. It’s shedding some of its legacy constraints step-by-step.
Coda: Which, you know, leads us to a final provocative thought for our listeners to maybe mull over. We’ve seen this huge engineering effort go into creating immortal objects, largely driven by the desire to eventually remove the GIL and enable better parallelism.
Odyssey: Right. Making objects inherently safer for concurrency. So here’s the question. If this trend continues, and more and more of Python’s core objects, and maybe even common application objects encouraged by new patterns, become truly immutable and immortal, objects that don’t need reference counting don’t need cycle detection, could the generational cyclic garbage collector, the source of so much of the latency pain we discussed today, could it actually become less and less important over time?
Coda: Interesting question. Could we reach a future, highly concurrent version of Python where the cyclic GC runs so infrequently or has so little work to do because most complex structures are built from immutable, immortal components that it essentially becomes irrelevant as a performance factor?
Odyssey: Could the ultimate victory in Python memory management be the slow, graceful retirement of the heavy GC hammer altogether?
Coda: That’s definitely something to think about. A Python where cycles are rare and GC pauses are a forgotten problem?
Odyssey: That would be quite a transformation.