Tech | The Single Pointer Revolution: How Linux Cgroups Changed Kernel Isolation
A technical episode on Linux cgroups, kernel accounting, resource isolation, containers, and operating-system abstractions.
Listen
Listen on available platforms
Episode text
Transcript
Overview
Linux cgroups, kernel design, resource isolation, containers, and operating-system abstractions.
Transcript
Coda: Welcome to the Deep Dive. This is where we take those really dense foundational technical papers, you know, the ones that basically built the systems we use every day, and we break them down for you. Today, we’re going deep, kernel-level deep, back to Linux in the mid-2000s.
Odyssey: Yeah, a critical time. If you use software today, and let’s be honest, who doesn’t? Maybe you’re spinning up containers, using the cloud, just managing the server. You’re relying on this hidden system that manages groups of processes. We often think about limits, right? Like how much CPU can this app use or memory limits for that VM? But the real question, the kernel question is, how does it actually organize those limits across groups of processes?
Coda: It’s a fundamental scaling challenge, really. The kernel’s juggling, I mean, thousands, potentially millions of individual tasks. But for resource management, especially virtualization, isolation, controlling just one task isn’t enough. You need policies that apply to a whole family of tasks. You need children to inherit limits from parents. And crucially, all this tracking, this membership stuff, it has to be practically free in terms of performance, especially on core things like fork and exit.
Odyssey: So our mission today, explore the first principles behind how Linux cracked this. We’re zeroing in on a specific, really groundbreaking proposal from 2007. It detailed a generic process grouping feature, initially called the containers framework.
Coda: Which, yeah, eventually evolved into what we know today as tick groups, control groups.
Odyssey: Exactly. And this proposal, it was aimed at the 2.623 kernel. It wasn’t just a new feature. It was about cleaning up a mess. Oh, definitely. It was a solution to like a looming complexity crisis. Before this, the kernel was getting bloated. Things were incompatible. Imagine you’re a developer, say, building a network bandwidth controller.
Coda: Okay. You basically had to invent your own way to track which processes belong to which network group. And you’d end up duplicating logic that was already in the memory controller or maybe the CPU scheduler. So everyone’s reinventing the wheel for grouping. Pretty much. And it wasn’t just messy code. It was fundamentally incompatible. If you had five different systems trying to track groups for five different resources. You have five different user APIs, five different sets of kernel hooks.
Odyssey: Exactly. Redundant pointers everywhere. It was unsustainable. So the goal here was unification. Build one. Generic base layer.
Coda: Okay. And this new mechanism, it had to be, well, everything. Low overhead, super feature rich, flexible enough for all the stakeholders, you know, the resource controllers limiting stuff, the isolation systems creating virtual views, everyone. So it needed to be the universal backbone.
Odyssey: Precisely. The idea was subsystem writers could finally focus just on their resource logic, the thing they actually cared about, and not get bogged down in the plumbing of drup management.
Coda: Okay. Let’s really unpack this using first principles. We said Linux was great at individual processes, but the weakness before this framework was efficient grouping, a unified way.
Odyssey: Yeah. If you look back at the mid-2000s, Linux could do some advanced stuff per process. But for groups, people were just making it up as they went along.
Coda: Right. And these different projects, they fell into roughly two big incompatible camps. And trying to merge them as they were, that was causing serious duplication in core kernel structures.
Odyssey: Okay. Let’s define those two camps. Because understanding the difference really highlights why this unified framework was so needed. Camp one. Resource control and monitoring.
Coda: Right. This is all about quantity, limits, and accounting. Mechanisms that track consumption, like how many CPU cycles did this group use? How much memory? Or mechanisms that actively impose limits. Maybe a hard cap, maybe dynamic throttling when there’s contention. And a key thing you mentioned from the source, the processes usually know they’re being controlled. It’s visible. Typically, yes. If your app hits a memory limit, it might get a signal or just slows down. That’s detectable behavior.
Odyssey: Okay. So that’s resource control. What was camp two?
Coda: Namespace isolation.
Odyssey: This is really the seed of what we think of as lightweight virtualization containers today. Ah, okay. Isolation mechanisms, they don’t primarily focus on limiting consumption. They add a layer of indirection, a translation, to how processes see the system. Things like process IDs, PIDs, or mount points, network interfaces, they get virtualized. So it’s about changing the view of the system.
Coda: Exactly. And the key feature here is kind of the opposite of resource control. It’s typically invisible to the processes inside. How so?
Odyssey: Well, a process inside an isolated environment might think it’s PID1, the main init process. It might think it has the whole file system root to itself. But really, it’s operating on this private translated view managed by the kernel. So you’ve got these two fundamentally different philosophies. One is about visible limits. The other about invisible virtualization. How did they bridge that gap?
Coda: They looked underneath. They realized, okay, despite the different goals, both camps need the exact same basic thing, a way to track process membership reliably. Both resource control and isolation, they’re just specific applications of a general model where some kernel subsystem does something different based on which group a process belongs to. The common element is defining that group boundary.
Odyssey: Right. Makes sense. Think about simple examples like really basic grouping, job control in your shell.
Coda: Okay. You run a command, maybe a pipeline with multiple processes. The kernel needs to efficiently track all the processes spawned by that single job. When you hit Shreddle plus C, it needs to know which ones to kill. It just needs to maintain that list efficiently as tasks are created and destroyed. Simple enough. Now contrast that with something like memory pressure tracking.
Odyssey: This is more resource control, but maybe without a hard limit.
Coda: Okay. You might just want to know when memory reclaim efforts, like the scanning level in Tridoforpeges, hit a certain threshold for a specific group, maybe for a particular customer’s virtual server. Ah, so you need the group to scope the alert.
Odyssey: Exactly. The grouping mechanism lets you notify user space, hey, memory pressure for this specific group is getting critical, not just the whole server is under pressure.
Coda: Okay, so if you don’t unify this, if developers keep building their own grouping systems, what are the big drawbacks?
Odyssey: The paper listed several.
Coda: Yeah. The first one hits user space right away. Incompatibility. You end up with different APIs for everything. The CPU scheduler uses framework A. The memory controller uses framework B. They can’t talk to each other. So trying to coordinate them, like setting a related CPU and memory limit for the same group, becomes a nightmare. A huge headache. Integrating systems that should work together becomes incredibly difficult because their underlying ideas of what constitutes a group might just conflict.
Odyssey: And internally in the kernel.
Coda: That’s where it really hurt. Every competing framework wanted its own pointer inside the task script.
Odyssey: That’s the main kernel structure for a process. It’s performance critical.
Coda: Right. And each framework needed its own hooks and fork and exit, also super performance critical paths, just to manage its own group structures and reference counts.
Odyssey: Which leads straight to co-bloop.
Coda: Yep. Kernel structures get packed with redundant stuff. Maintenance becomes a nightmare. And every time a process starts or stops, which happens constantly on a busy server, you pay this increasing overhead tax.
Odyssey: So the container framework proposal was about stopping the bleeding.
Coda: Exactly. Abstract away the pain. Provide one single general mechanism, the abstract container. Handle all the low-level, high-performance tracking and partitioning. Let the subsystem writers focus on their actual job, managing the resource itself. It was, well, a move towards architectural sanity.
Odyssey: Okay.
Coda: Okay.
Odyssey: So they had this vision for a unified grouping mechanism. But to make it work for everyone, it needed a really solid set of requirements. What were the non-negotiables?
Coda: What design criteria had to be met?
Odyssey: These requirements were crucial. If they missed any of these, the framework could have just ended up being another limited specific grouping tool, not the universal layer they needed. Makes sense. What’s requirement one?
Coda: Multiple independent subsystems. The framework itself couldn’t be opinionated about resources. It had to act like an intermediary, kind of like the Linux VFS, the virtual file system layer. Oh, so.
Odyssey: Well, VFS handles common file operations open, read, write, and then passes the specific request down to the actual file system driver, like xme4 or xfs. This framework needed to do the same for grouping. Handle common stuff like creating a group, destroying it, processes entering or leaving. And then notify the specific subsystems.
Coda: Exactly. Pass notifications to the clients, the memory controller, the network isolator, whatever. Hey, a process just joined this group you care about. And it needed to be flexible in terms of which subsystems were active.
Odyssey: Absolutely. You had to be able to selectively enable them. Maybe bind the CPU controller, but not the memory one, to a group. And you needed to control this both at compile time and run time. Modularity was key.
Coda: Okay. Requirement two?
Odyssey: Mobility. This is pretty fundamental for management. A privileged user, like root or an admin, must be able to move a process from one container to another within the same hierarchy or partition. Think load balancing or just reorganizing things. Seems straightforward.
Coda: Yeah.
Odyssey: But there was a nuance.
Coda: Yeah. They realized pretty quickly that not all subsystems want free movement. Some virtual server setups, for example, might need to lock a process into its container at creation. Like, this is the init process for this secure environment.
Odyssey: It cannot move. Ah, okay.
Coda: So the framework couldn’t just mandate universal mobility. It had to be configurable per subsystem. The memory controller might allow moving tasks any time, while a security isolation controller might forbid it after creation. Flexibility again.
Odyssey: Which leads right into requirement three, I guess. No. Inescapability. The security aspect.
Coda: Precisely. Once a process is in a container, either inherited from its parent or moved in by an admin, that process and any kids it spawns should not be able to just leave on their own.
Odyssey: Right. That would break the whole point of limits or isolation.
Coda: Totally. The boundary has to be firm unless deliberately changed by someone with the right permissions. Often, this was tied into the file system permissions of the control interface itself. You need guarantees. If you assign 4GB of RAM to a group, those processes can’t just unilaterally decide to jump ship to an unlimited group.
Odyssey: Okay. Makes perfect sense. Requirement four. The user interface. That sounds tricky. It was. Extensible UI. Subsystems have wildly different needs. A memory controller might just need a couple of numbers. Sock limit. Hard limit. Whereas a CPU controller might need, what, a complex bit mask for specific cores?
Coda: Exactly. Or maybe a notification system just needs a threshold level. The framework couldn’t possibly impose one single data format for configuration. It would be too restrictor.
Odyssey: So they considered two main options for the UI.
Coda: Yeah. Option one. A new kernel API. Maybe a new set of system calls. Get property X. Set property Y. That offers uniformity. Maybe slightly better raw performance in theory.
Odyssey: But they didn’t go for that. Nope. They overwhelmingly preferred option two. A file system interface. This was directly inspired by Kleefeusets, which was already using this model successfully. So directories represent containers. And you read or write special files inside them to configure things.
Coda: That’s the one. Flexibility 1 out. A file system can handle any kind of data format in those control files. Numbers, strings, bitmasks, whatever the subsystem needs. Plus, and this is huge, you can manage it using standard Unix tool. Ah, so LZLP MBDR Echo Cap. Your basic toolkit. Admins already know how to use them. No need to learn a new complex utility for every single subsystem. It lowers the barrier to entry enormously and makes scripting much simpler.
Odyssey: That’s a really big practical advantage. And permissions. Built in. By using a file system hierarchy, you leverage standard Unix file permissions for controlling who can create containers, move tasks, or change settings. It solves the delegation problem neatly. Clever.
Coda: Okay, last one. Requirement 5. Nesting. Hierarchies.
Odyssey: This is essential for delegation. The main system might have a root container representing the whole machine. It should be able to carve off resources, say, 50% CPU, specific memory nodes, and assign them to a child container. And that child container could then subdivide its resources further.
Coda: Exactly. Think of a hosting provider allocating resources to a reseller, who then allocates smaller chunks to individual customer virtual servers. You need that hierarchical structure. But like mobility, maybe not everyone needs nesting.
Odyssey: Right. Some simple controllers might just want a flat structure. So again, configurability was key. The framework had to let subsystems choose whether they support nesting within their specific hierarchy or partition.
Coda: Okay. So those five multiple subsystems, configurable mobility, inescapability, file system UI, and selective nesting. Those were the design pillars.
Odyssey: Yeah. Get those right. And you have a foundation that’s flexible and robust enough for pretty much anything.
Coda: Okay. Now we get to the really tricky bit. Building the container object itself, holding some data, that’s relatively easy. The hard part, the real intellectual challenge, was figuring out how these containers relate to processes when different resources, like CPU versus network, might need completely different groupings.
Odyssey: Right. The partitioning problem.
Coda: Exactly. The core rule they established is any given process at any point in time must belong to one and only one container for each type of partitioning. They called these partitions or hierarchies. So a process might be in the high priority CPU group, but the bulk transfer network group simultaneously.
Odyssey: Okay. Now, early attempts tried to simplify this. They thought maybe we can just have one partitioning scheme for everything. You create a group for CPU and bam, that same group structure automatically applies to memory, I.O., everything. Down simpler, maybe. Simpler, but way too limiting. The paper makes it clear this failed quickly because real world resource needs just aren’t monolithic like that.
Coda: So the framework had to support multiple independent ways of partitioning the processes. Yes. Multiple hierarchies. And the best way to see why this independence is crucial is to look at the case studies they included in the proposal.
Odyssey: Right. Let’s dive into those. Case study A, the university server. Classic timesharing setup. You’ve got students, staff, system tasks, all needing resources. In the requirements clash, right?
Coda: Right. First, CPU and memory. Those need to be partitioned based on who owns the process, user ID. You want guarantees for staff, limits for students, protection for system tasks.
Odyssey: That’s an identity hierarchy. System, staff, students. Makes sense, but then there’s network traffic.
Coda: Yeah. Network control needs partitioning based on traffic content or maybe destinations. Like limit total www browsing bandwidth across everyone or maybe prioritize NFS file sharing traffic over other stuff. This forms a content hierarchy. www, NFS, other.
Odyssey: Okay. I see the conflict. If you forced a single hierarchy. It would be a configuration nightmare. You’d need a container for every single combination. Staff www, staff NFS, student www, student NFS, system www. Even if the CPU limits for staff have absolutely nothing to do with the global www limit. Unmanageable.
Coda: Totally.
Odyssey: So the solution shown in their figure 1A is independent hierarchies. You have one hierarchy for CQ sets and memory based on identity, SIS, staff, students, and a completely separate orthogonal hierarchy for network based on content, www, NFS, other. They operate on the same processes, but independently.
Coda: Okay. That definitely proves you need independent partitions sometimes. Then why would you ever want to merge them?
Odyssey: That leads to the second case study.
Coda: Exactly. Case study B, the hosting server.
Odyssey: This is a commercial setup. A provider sells blocks of resources, maybe NUMA nodes, to resellers.
Coda: Okay. Reseller 1, R1, reseller 2, R2.
Odyssey: Right. And the provider uses CPU sets to give R1 and R2 their guaranteed chunk of hardware-specific CPUs, specific memory nodes. Then, within their allocation, the resellers spin up virtual servers for their customers, VS1, VS2, VS3, VS4. And those virtual servers need limits too.
Coda: Yeah. They need namespace isolation, memory limits, network limits, and CPU limits within the reseller’s allocation.
Odyssey: So what happens if you only allow independent hierarchies here, like in figure 1B of the paper?
Coda: It becomes operationally painful. The structure for R1, R2, and then VS1, VS4 underneath is the same for CPU sets, memory, network, and isolation. If each needs its own hierarchy, the hosting provider has to create and configure that identical tree structure four separate times. Ouch. So every time a reseller adds a new virtual server, the admin has to make four directories, edit four sets of control files.
Odyssey: Exactly. Massive duplication of effort. Maintenance gets complex. Auditing is harder. It’s just inefficient.
Coda: So what’s the better way?
Odyssey: The preferred approach, the multi-subsystem hierarchy. This allows you to bind multiple subsystems to the same hierarchy structure if their grouping logic is the same for all processes, if the partitioning is, as they called it, isomorphic. And in the hosting example, the boundaries for CPU sets, memory, network, isolation are all the same. R1, R2, then VS1, VS4.
Coda: Right.
Odyssey: So the solution, figure 2B, is bind all four subsystems to a single hierarchy. You create the R1, R2, VS1, 4 directory structure once. Then you tell the kernel, attach the CPU set controller, the memory controller, the network controller, and the isolation controller to this single tree. Configuration done once. Management simplified drastically. Cuts the effort by 75% in this case. And maybe even more importantly, it avoids nasty race conditions. How so?
Coda: Think about moving a process, say, from VS1 to VS2. If you had independent hierarchies, you might have to do it in multiple steps. Move it in the network hierarchy, then move it in the CPU hierarchy. What if a child process is forked right between those two steps?
Odyssey: It could end up in VS2 for network, but still in VS1 for CPU. Inconsistent state.
Coda: Exactly. Binding them to one hierarchy means the move is a single atomic operation managed by the core framework. Much safer. So this analysis, these case studies, they really show the framework needed both options. Independent hierarchies when needed, but multi-subsystem hierarchies for efficiency and safety when groupings align. That was the key insight for partitioning. And there was one last complication they had to factor in. Non-process references. What does that mean?
Odyssey: It’s about accounting. What happens if a container allocates, say, a gigabyte of kernel memory, maybe for network buffers or file caches, and then all the processes using that container exit?
Coda: Hmm. The container is empty of tasks.
Odyssey: Right.
Coda: But the resources are still allocated. The memory accounting state, the socket buffers, they still exist and belong to that logical group. You can’t just destroy the container object yet. Because you’d lose the accounting.
Odyssey: Exactly. The framework needed a way to reference count these external objects, pages, file handles, sockets. A container couldn’t be removed, even if empty of tasks, as long as these non-process references existed. Its destruction had to be blocked until that count dropped to zero. This needed to be built into the core design.
Coda: Okay, so we have this demanding set of requirements. Flexibility, nesting, tricky partitioning, non-process references. Now, it’s important to remember, as you said, they weren’t starting from scratch. They looked hard at what already existed, both the successes and the failures.
Odyssey: Absolutely. The history really shaped the design. You learn what to borrow and, crucially, what mistakes to avoid repeating. The obvious starting point was classical Unix grouping.
Coda: Right. Why not just use user IDs and group IDs?
Odyssey: UID, GID. Or session and process groups, SIDPGRP. The paper lays it out clearly. They just don’t work for this. UID, GID are way too broad. One user might run lots of different jobs that need separate resource controls. And virtual servers mess it up, too, right?
Coda: Processes inside might need different UIDs than the host sees.
Odyssey: Exactly. It breaks down. And SIDPGRP, while closer to tracking jobs, have a fatal flaw for this purpose. Under traditional Unix rules, processes can change their session ID or process group ID. Ah, but the container boundary needed to be inescapable. Rigid.
Coda: Right. You couldn’t just remove the ability for processes to change SIDPGRP because that would break tons of existing applications that rely on that behavior.
Odyssey: So these classical mechanisms were out. They needed something new, dedicated, and fundamentally rigid.
Coda: Which brings us to steep sets. That was already in the kernel.
Odyssey: Yeah. Seep sets was the main container-like system in mainline Linux at the time, managing CPU affinity and memory node placement. And its big contribution was the user interface model. Huge contribution. C-Posets proved that the pseudofile system API was a winner for this kind of resource management. Create directories for groups. Write to control files for settings. Write PIDs to a tasks file to move processes. Simple, familiar, scriptable.
Coda: Exactly. It worked. It was flexible. It provided the blueprint for the user-facing part of the new container framework.
Odyssey: But they also learned from things that didn’t work so well. Or systems with different philosophies. Definitely. There were systems like Eclipse and Resource Containers. They both did hierarchical grouping. Eclipse actually used the independent hierarchies model, while Resource Containers forced a single hierarchy.
Coda: So they showed the trade-offs there. And then there was PEG from SGI Process Aggregates.
Odyssey: Right. PEG was interesting because it was a generic container mechanism. But its design allowed really free-form, almost arbitrary connections between processes and containers.
Coda: Which sounds flexible, but… It came at a high cost. Because the structure was so dynamic, actually accessing the container state for a given process was much more expensive computationally. You couldn’t just follow a fixed pointer. And crucially, the processing needed on fork and exit was significantly more complex and costly. For a foundational kernel mechanism that needs to be super fast on those paths, that was a non-starter.
Odyssey: So the lesson from PEG was, keep the access path to container state fast to predictable, low overhead is paramount.
Coda: Absolutely. Then you had the more opinionated resource control frameworks like resource groups, CKRM, and bean counters. These were more focused purely on limits.
Odyssey: Yeah. And they enforced a particular model. CKRM, for instance, was often about specifying limits as a fraction of the parent’s resources.
Coda: Which is fine, if that’s what you need. But not general enough. Not general enough to be the base layer. Trying to implement something like CEPA sets, which deals with absolute hardware assignments, CPU 3, memory node 1, on top of a framework designed for fractional limits. Almost impossible. They were too specialized. They couldn’t host all the different kinds of subsystems needed.
Odyssey: Okay. And finally, the really influential related work came from the isolation side. NSProxy. Yes. This was key. NSProxy dealt with managing kernel namespaces, PID namespaces, network namespaces, IPC, etc. for virtual servers. And namespaces have the same fork exit problem, meaning reference counting.
Coda: Exactly. If every task needed a separate pointer and reef count for every single possible namespace type, the task struct would explode and fork exit would grind to a halt.
Odyssey: So what did NSProxy do?
Coda: It introduced the struct NSProxy. The task struct got just one pointer pointing to this NSProxy structure. Inside the NSProxy were all the printers to the actual namespace objects. Ah, indirection. Indirection and sharing. So, tasks that shared the exact same set of active namespaces pointed to the same shared NSProxy structure. So fork exit only had to touch one reference count.
Odyssey: Precisely. One get on fork, one put on exit for the NSProxy. It was a brilliant architectural tradeoff. Accept one extra pointer deereference during namespace access in exchange for huge savings in memory space and fork exit overhead. And that became the model for the container framework’s core structure.
Coda: Absolutely. It proved you could manage complex per task state efficiently using a shared reference counted intermediate structure. That was the critical technical inspiration.
Odyssey: Okay, we’ve got the requirements, the history, the inspiration from CP sets, and especially NSProxy. Let’s get into the nuts and bolts. How did they actually build this thing in the kernel?
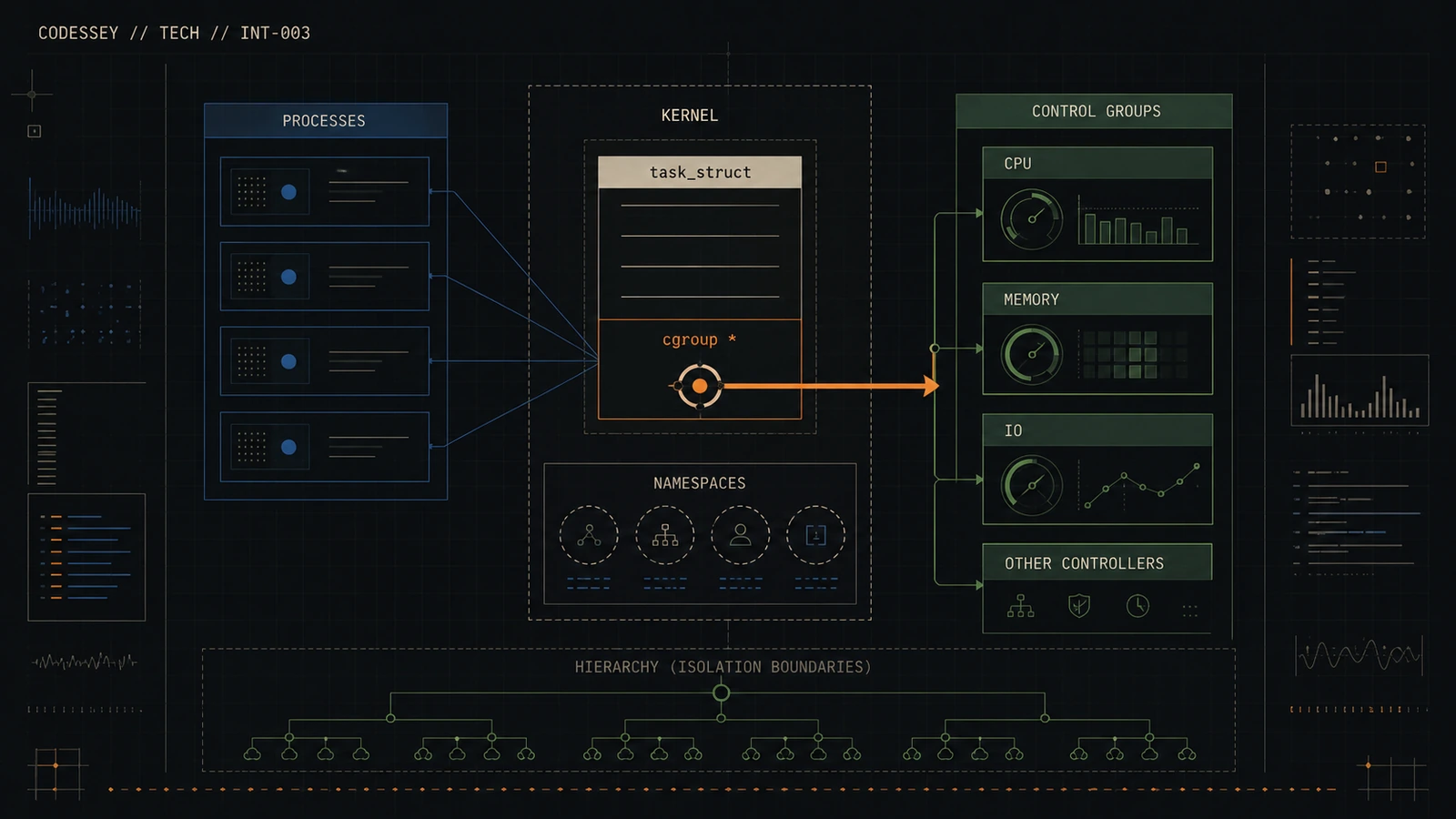
Coda: Favoring that multi-hierarchy approach but keeping it lightning fast. The design centers around four new core kernel structures. They work together to handle the grouping abstractly. Insulating the subsystem writers from the messy details.
Odyssey: Right. Structure number one. The container struck itself. Think of this as the node in the hierarchy tree. It knows its parent, its children, its siblings within a specific hierarchy. But critically, it’s purely structural. It holds no resource-specific data itself. Just pointers. Pointers to its family in the tree and pointers to the various subsystem states attached to it. And another key point for performance. The container struck does not keep a list of all the tasks inside it.
Coda: Why not?
Odyssey: Wouldn’t that be useful?
Coda: Useful maybe, but expensive to maintain on every fork and exit. Instead, if some tool needs the list of tasks, it can reconstruct it by walking the system’s task list and checking each task’s container pointer. Slower for that specific operation, but keeps the common paths fast.
Odyssey: Okay. Structure two. Container subsystem. This represents the type of subsystem, like the memory controller or the network isolation controller. It’s registered once, usually at boot or compile time. This structure is basically the contract, telling the core framework how to talk to this kind of subsystem. And it does that using callbacks.
Coda: Exactly. It’s full of function pointers callbacks that the framework calls at specific events.
Odyssey: This is where all the duplicated logic from the old systems got consolidated. What kind of events need callbacks?
Coda: All the key lifecycle and membership moments. Create and destroy when a container directory is made or removed in the file system. CanAttach this is the crucial permission check before a process is moved. The subsystem gets to say yes or no based on its own rules. Like you can’t move this process here because it would exceed the memory limit.
Odyssey: Precisely. Then, if CanAttach succeeds, the attach callback is called when the move actually happens. Then you have the really performance sensitive ones. Fork and exit. These let the subsystem allocate or free its own state when a task is created or dies within one of its containers. And a couple more. Populate lets the subsystem create its specific control files, like memory.limit and bytes, in the container directory. And bind handles attaching the subsystem to a particular hierarchy when it’s mounted.
Coda: It externalizes all that integration glue. Got it. Structure 3. Container subsistate.
Odyssey: Okay, this is where the actual resource data lives. It’s the state associated with a specific subsystem for a specific container. So if you have container A and the memory subsystem is attached, there will be a container subsistate object holding the memory usage and limits for container A. And what important fields does this base type have?
Coda: Two main ones. First, a pointer back to its parent container object. Perfect.
Odyssey: This is vital for hierarchical subsystems that need to walk up or down the tree, maybe to enforce limits relative to the parent. And second. The refrent.
Coda: This is the counter for those non-process references we talked about earlier. Ah, the one that keeps the container alive, even if empty, as long as resources like pages or sockets are still referencing it.
Odyssey: Exactly. If that refrent is non-zero, the framework won’t let you jimdeer the container, protecting the accounting state.
Coda: Okay, container, container subsist, container subsistate, now the linchpin, the structure that makes it all fast. CS group. Container subsystem group.
Odyssey: This is pure NSProxy inspiration. The problem. The task struct is sacred ground. You cannot just add dozens of new pointers to it, one for every possible resource controller state. The memory overhead and cache impact would be killer. So how does every task get access to potentially dozens of different container subsistate pointers without bloating task struct?
Coda: Indirection and sharing, just like NSProxy. The kernel adds only one new pointer to task struct. It’s typically called SIG groups or containers.
Odyssey: That’s one pointer. Just one. That pointer points to a SIG group structure. And this SIG group structure contains an array of pointers, one slot for every registered subsistate in the kernel. Each slot points to the relevant container subsistate for that task.
Coda: Okay, so the SIG group bundles all the state pointers together.
Odyssey: Exactly. And here’s the magic. Tasks that share the exact same set of container memberships across all active hierarchies. They show the exact same SIG group object. Ah. Reference counting on the SIG group. You got it. Massive space saving, especially in big systems where many tasks live in the same set of containers. So that’s the tradeoff again. Save space, simplify for exit reference counting at the cost of one extra pointer lookup when you need to access the state.
Coda: How big a deal was that performance optimization for fork and exit?
Odyssey: It was absolutely critical. Instead of iterating through, say, 10 or 20 subsystem pointers doing 10 or 20 reference count updates, the code just does one atomic CREF get on the shared SIG group during fork and one CREF put during exit. Super efficient. Extremely. If the Trees group reference count drops to zero on exit, the framework knows it can free the SIG group and trigger the destruction of the associated subsystem states. And if no subsystems are actually registered and attached, the overhead is basically negligible just to that single reef count operation.
Coda: Okay, but what about accessing the state from within the kernel?
Odyssey: Like the scheduler needing to know CPU limits or the memory allocator checking usage. They need instant access, right?
Coda: They can’t wait. You mentioned user space configuration uses a global lock, container mutex. That sounds too slow for hot paths.
Odyssey: Absolutely too slow. That global lock is fine for configuration changes via the file system, which are relatively infrequent. But for performance critical paths inside the kernel, they needed something lockless.
Coda: This is where RCU read copy update comes in. Ah, RCU. The kernel’s magic for avoiding locks on read paths. Pretty much. The container structures, particularly the C group and the pointers it holds, are designed to be managed using RCU. When something changes, a process moves, a limit is updated. The update happens under the protection of RCU mechanisms. So readers. Readers, like the scheduler or memory management code, just enter an RCU read side critical section.
Odyssey: It’s very lightweight. Inside that section, they’re guaranteed that any painters they read from the C group will remain valid and stable for the duration of their read operation. They can access the state pointers instantly without taking any locks. So, one pointer in direction, task truck, mama, seize group, amounted, container, subsea state, protected by RCU for safe lockless reads.
Coda: That’s the core of the performance story. It balances the need for complex organization with the absolute requirement for minimal overhead on the kernel’s fastest operations. RCU is the enabling technology that made the shared structure approach viable for performance critical state.
Odyssey: Okay, we’ve got the internal architecture laid out. Hierarchical, flexible, RCU protected for speed. Let’s bring it back to the surface. What does the user actually see and interact with?
Coda: And how did this framework prove itself in practice by integrating real-world subsystems?
Odyssey: The UserSpace API, as we discussed, followed the SpeedSits model because it worked so well. The file system model. Familiarity was key for adoption. So, how does an admin use it?
Coda: Step one is creating a hierarchy.
Odyssey: Right. Hierarchy creation. You use the standard mount command. You specify the type as C group or C group 2 nowadays. And you pass options to say which subsystems you want to bind to this particular hierarchy mount point. Like OCP memory to create a hierarchy controlling both CPU and memory together. Multi-subsystem hierarchy mount.
Coda: Exactly. Or you could mount just two in a demo for a separate network classification hierarchy. Then, container creation is literally just Infadir inside that mount point. Creating a directory automatically creates a new child container object in the kernel. And moving processes. Process movement. You echo a process ID, PID, into the special PASCs file inside the target containers directory.
Odyssey: And that’s where the checks happen.
Coda: Yep. The framework intercepts that right. Before actually moving the process, it calls the can-attach callback for every subsystem bound to that hierarchy. Only if they all return yes, does the framework atomically update the process’s C screw pointer. Safe and controlled. How do you see what’s going on?
Odyssey: Reporting. Standard tools, mostly. You can cat the control files to see limits or usage. And there’s a special file in PROC for each process. PROC PIDC group, or PROC PID container in the original proposal’s naming. This lists the path to the process’s container within each active hierarchy it belongs to. And destroying containers. Just Armdeer.
Coda: But the framework enforces safety. Armdeer will fail with IBBY use, WISE or Resource Busy, if the container still has tasks in it. Or if that non-process refren we talked about is still greater than zero, meaning some kernel resource is still holding on to its accounting state.
Odyssey: Okay. Seems robust. Now the proof is in the pudding. How did it handle integrating actual subsystems?
Coda: Let’s start with a simple example. CPU accounting. Cofact. Cofact was designed as like the minimal viable subsystem, purely for demonstration. Its only job was tracking total CPU time used by processes in a container and maybe recent load. No limits, just accounting. And the key takeaway was the code size.
Odyssey: Yeah. The paper highlights it. Implementing this entire new functional subsystem took only a 250-line patch. Wow. That’s tiny for a kernel feature. It’s the ultimate validation of the framework’s abstraction. All the hard parts, hierarchy, fork-exit handling, file system interface plumbing were handled by the generic code. The ScoopWalk developer only had to write the logic to hook into the scheduler’s timing updates and increment the write counter in its container subsystem. Poor that the abstraction worked.
Coda: Now for the big one. Integrating CPU sets itself. This was huge, politically and technically. Taking the existing mature KrimiSets system and porting it to run on top of the new generic framework it had inspired. And the results?
Odyssey: Astounding, really. The port allowed them to remove about 30% of the original CP sets code. Removed code? How?
Coda: Because that 30% was all the duplicated logic for managing process groups, tracking membership, handling hierarchy, dealing with fork-exit, all the stuff the generic container framework now did for it. So it wasn’t just good for new systems. It actually cleaned up existing complex code.
Odyssey: Exactly. It fulfilled that initial goal of reducing kernel bloat and consolidating redundant mechanisms. And it proved the framework was flexible enough to handle the complex configuration needs of CP sets, like those hardware bit masks. What about those other more opinionated frameworks like Ries groups and bean counters? Did they just disappear?
Coda: Not exactly. They adapted. They realized they couldn’t compete with the generic base layer in terms of efficiency and universality. So instead, they were re-implemented as container subsystem libraries. Libraries. Meaning?
Odyssey: They stripped out all their own internal group management code. They became clients, consumers of the generic container framework. Their library code would then translate the framework’s basic raw file read-write interface into their own specific higher-level structured API, like dealing with fractional limits or complex policies. Ah, so user space could still interact with the familiar Ries groups or bean counter concepts. But underneath, it was all running on the standardized, efficient container-based layer.
Coda: It showed how different resource models could coexist on top of the common foundation. Unification in the kernel, flexibility in user space abstractions. Very neat. Lastly, the vision for NSProxy container integration. This wasn’t just resource control, right? This was about isolation.
Odyssey: Yeah, this was more speculative in the original paper, but showed the framework’s potential beyond just bean counting. The idea was simple. Link namespace creation directly to container creation. How would that work?
Coda: When a task creates a new set of namespaces, maybe using clone with namespace flags, or the unshare system called the kernel hooks would trigger a call into the container framework, something like container clone. And container clone would?
Odyssey: Automatically create a new dedicated subcontainer, maybe nested under the parent’s container, specifically for this new set of namespaces. And then it would move the task that just created the namespaces into this new container. So you’d automatically get a container representing each isolated environment.
Coda: Exactly. The container hierarchy would naturally mirror the namespace hierarchy. It provided a clean, manageable way to see which processes belong to which isolation domains, right alongside the resource control groupings in the same VFS structure. That sounds incredibly close to how modern container runtimes work, managing both isolation and resources together.
Odyssey: It really was the conceptual seed. It showed the container framework wasn’t just for limits. It was a truly generic grouping mechanism capable of organizing processes based on isolation boundaries just as easily as resource boundaries. Hashtag outro. So if you boil it all down, that 2007 containers framework proposal was about bringing order to chaos. It looked at all these different incompatible systems trying to group processes for resource control, for isolation, for hardware affinity.
Coda: And it said, stop duplicating the hard part. The hard part being tracking membership efficiently.
Odyssey: Right. It provided that single, high-performance backbone for process tracking, handling, fork, exit, hierarchy permissions, abstracting all that complexity away so subsystem writers could focus on their actual resource logic. And this work, leading to Cree groups, was just fundamental for the Linux kernel. It successfully blended lessons from everywhere that Cree sees its file system model, the need for independent partitions shown by the case studies, and crucially, that low overhead shared structure trick borrowed from its proxy.
Coda: It really standardized the whole concept. Processes can be grouped hierarchically in different ways for different needs and controlled efficiently enough that it can sit right at the core of the kernel next to the scheduler and memory management. Modern Linux containers, Kubernetes, systemed resource control. None of it would be feasible or performant without this foundation. We have seen how it handles resource limits and isolation views with the same core mechanism, minimizing the performance hit.
Odyssey: It’s kind of amazing when you think about it, how much relies on this organizational layer. The entire cloud computing paradigm, really, with millions of isolated workloads running on shared kernels. It hinges on it. Think back to that core constraint. How do you track potentially dozens of resource states per task without making task huge or fork and slow?
Coda: Their solution, that single-squeeze group pointer, shared structures, reference counting, and RCU for lockless reads, was just an incredibly elegant piece of engineering. That architectural decision, that trade-off made almost two decades ago. It’s basically the invisible engine driving a huge chunk of the world’s computing infrastructure today. So here’s a final thought for you. How many layers of abstraction, how many complex cloud services and container orchestration systems, are ultimately running on top of that one tiny, heavily optimized, a task group pointer inside the Linux kernel?
Odyssey: How many layers have a large scale?
Coda: How many layers have a large scale?