Tech | How uv Is Rewriting Python Packaging
How the Rust-based uv package manager is replacing pip, virtualenv, pip-tools, Poetry, and more with a single 100x faster binary — from SAT-solving dependency resolution to content-addressable storage.
Listen
Listen on available platforms
Episode text
Transcript
Overview
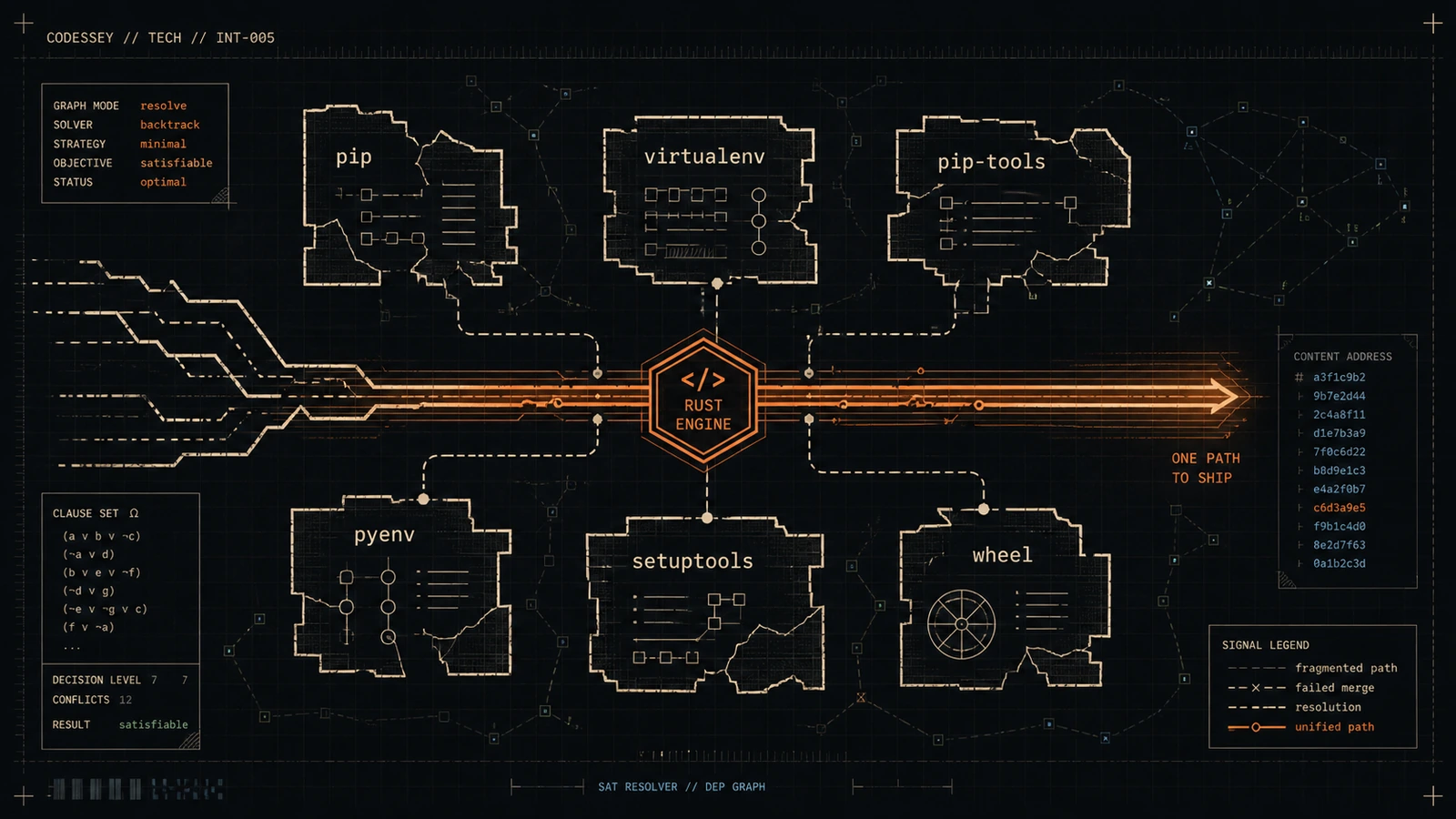
uv, the Python packaging tool written in Rust by the Ruff team, is reshaping Python packaging. This episode covers how uv aims to replace pip, virtualenv, pip-tools, and more with a unified, fast, single-binary workflow.
Transcript
Coda: Imagine, right, handing a new developer a massive, incredibly heavy key ring on their very first day. Oh, this is going to be a good analogy. You look them in the eye and say, okay, so the brass key, that opens your car door, but you have to use the silver key to actually start the engine.
Odyssey: Right, and don’t mix them up.
Coda: Exactly, and then you say, if you want to put groceries in the trunk, well, you actually need to call a completely different manufacturer to mail you a third key. Sounds perfectly reasonable. Like, the kicker is, oh, by the way, if you accidentally use the brass key in the ignition, the entire car literally bursts into flames. You would think that dealership was, like, completely out of its mind.
Odyssey: Yeah, I mean, that absurd, hyper-fragmented reality is basically exactly how Python developers have been working for the better part of a decade. It’s just wild when you step back and look at it.
Coda: It really is. We completely normalized a workflow where, you know, simply getting a project off the ground required duct-taping together half a dozen fundamentally incompatible tools. All while just praying an invisible system update didn’t break the entire chain.
Odyssey: Right, exactly. So, welcome to this deep dive. Today, our mission is to completely deconstruct a piece of technology that is honestly rewriting the physics of the Python ecosystem. I don’t think that’s an overstatement. I don’t think so either. We are unpacking of the staggeringly fast Rust-based Python package and project manager developed by Astral. And we are going to pull this apart from first principles for you today. Yes, exactly. If you’re a beginner, we’ll explain the historical trauma of Python packaging and why things get so messy.
Coda: But we are also going to descend deep into, like, distinguished engineer territory. Oh, absolutely. We’ll be tearing open Rust concurrency models, exploring the operating system internals of content-addressable storage, and breaking down the mathematical SAT-solving algorithms that actually power dependency resolution. But to truly appreciate the surgical precision of what Astral has built, we first have to, you know, examine the trauma of the old guard. We have to talk about the trauma. Let’s look at that curing you mentioned.
Odyssey: For years, just to get a simple Hello World application into a professional reproducible state, you had to navigate this insane obstacle course of distinct utilities.
Coda: Right. Like, first you needed something like pyenv.
Odyssey: Exactly. Just to install and manage the Python interpreter itself. Because touching the default system Python on a Mac or a Linux machine is, well, it’s a guaranteed recipe for bricking your operating system’s internal utilities. Oh, man. I felt that pain firsthand. You accidentally upgrade a system-level dependency, and suddenly, like, your computer’s terminal won’t even open.
Coda: Yeah. It’s terrifying. So you install pyenv. But pyenv works by injecting these things called shims, basically fake executable files, into your system’s path. So it’s intercepting the commands.
Odyssey: Right. Every single time you type Python, the operating system hits the shim, which then runs a bash script to figure out which actual Python binary to forward the command to.
Coda: Which just adds overhead before the code even begins to execute.
Odyssey: Exactly.
Coda: And that’s just the interpreter layer. Once you safely have Python, then you face the environment isolation problem. Because you cannot install your project’s dependencies globally. No, absolutely not. Or Project A will just overwrite the exact libraries that Project B needs.
Odyssey: Right. So you bring in virtual and venv or, you know, the built-in venv module. And what do those do under the hood?
Coda: They create isolated directories by symlinking the Python binary and setting up a localized site packages folder. But, and this is the crazy part, venv doesn’t actually install anything on its own. Nope. For that, you have to bring out pip. The classic pip install.
Odyssey: Yeah, you run pip install, which reaches out to the internet, pulls down the files, and puts them in that isolated folder. But pip historically lacked a robust way to lock down exact reproducible versions of the entire dependency graph for a whole team.
Coda: Which, of course, birthed yet another tool. Naturally. Enter pip tools. You’d write this vague requirements.in file and then run pip compile to generate a strict requirements.txt. But wait, the sprawl continues. Oh, it does. Because if you wanted to install a global command line tool written in Python, like, say, the Black formatter or the Flake8 Linter without polluting your global environment. Then you needed pipx.
Odyssey: Right. And if you wanted to orchestrate all of this metadata into a modern unified configuration, you were reaching for wrappers like Poetry, Rye, Hatch, or PDM.
Coda: It is genuinely an exhausting list, just to say out loud.
Odyssey: It is. But, you know, when I was looking through the architectural analyses of these legacy tools for this deep dive, I noticed a fundamental structural flaw that ties all of this frustration together. The circular dependency problem. Yes. All of these legacy tools were written in Python. And that is the core architectural bottleneck right there. You need a fully functioning, pristine Python environment just to install and run the tools that are supposed to manage your Python environments.
Coda: It’s like needing scissors to open the package that the scissors came in.
Odyssey: Exactly. It creates massive bootstrapping friction. And worse, it introduces what we call the interpreter startup tax. Let’s break that tax down for a second because I think it’s invisible to most developers until they wonder why their continuous integration pipelines are taking, like, 20 minutes.
Coda: Yeah. It’s a silent killer. When you type a command like pip install, the operating system doesn’t just run the logic instantly.
Odyssey: Right. It has to call os.execve to spawn a new process.
Coda: Right. And then it loads the CPython interpreter binary into memory. It dynamically links the system’s C libraries. And then the interpreter has to initialize its own internal state, right?
Odyssey: Yes. It has to parse the sys.path to figure out where libraries live, read the file system to discover installed modules, and compile Python source code into bytecode. All of that happens before a single line of package management logic actually executes. Yes. And in a modern CI/CD pipeline, you might be invoking Python-based tools dozens of times across different stages.
Coda: Right. Like linting, formatting, type checking, building, testing.
Odyssey: Exactly. You are paying that heavy initialization tax, which can be hundreds of milliseconds over and over again. It compounds into incredibly slow deployment times. And this is the exact structural flaw that uv was designed to exploit and eliminate.
Coda: Precisely.
Odyssey: Yeah. Because uv isn’t written in Python.
Coda: Right. It’s a single statically compiled binary written entirely in Rust.
Odyssey: Which means it does not require a pre-existing Python interpreter to function at all. It breaks the circular dependency entirely. You download this one single executable file, and it acts as the master key. It handles fetching the interpreter, establishing the virtual environment, mathematically resolving the dependencies, and executing the tools. The transition path Astral designed for this is remarkably pragmatic, too.
Coda: It really is. Usually when a new technology promises a 100x performance increase, the assumption is that you have to rewrite your entire code base to adopt it.
Odyssey: Right. The classic migration weekend from hell.
Coda: Yeah, exactly.
Odyssey: Yeah. But uv avoids that adoption barrier by offering two distinct operational modes. The first is the uv pip interface.
Coda: Which is a drop-in API replacement for the legacy pip and pip-tools workflows, right?
Odyssey: Yeah. So wait, if I have an ancient shell script in my company’s Jenkins server that just reads pip install-R requirements.txt, I can literally just type the letters U and V in front of that command, change nothing else, and the pipeline still works.
Coda: It doesn’t just work. It operates in a fraction of the time. The benchmarks from our sources are just staggering. I saw those. Creating a standard virtual environment with python -m venv typically takes about two full seconds.
Odyssey: Yeah, largely due to that interpreter startup tax we talked about and the I/O cost of copying standard library files. But running a venv accomplishes the exact same task in roughly 35 milliseconds.
Coda: It is practically instantaneous. That fundamentally changes the physics of local development. I mean, if creating an environment goes from being a deliberate slow task to a sub-second blip, you stop treating virtual environments as precious, fragile things.
Odyssey: Right. You just tear them down and rebuild them constantly without thinking.
Coda: But the uv pip interface is just the backward-compatible mode, right?
Odyssey: The real paradigm shift is the second interface. Yes, the uv project mode.
Coda: This is the modern unified standard where U replaces Poetry, PDM, and pipx all at once. So you use uv init to bootstrap a new repository.
Odyssey: Yep, and you use uv add to append dependencies. What about the Python version itself?
Coda: You use uv python install to fetch specific interpreter versions. And then uv tool run, or its shorthand, uvx, to execute global tools in isolated ephemeral environments. I have to admit, when I first read about this unified tool concept, my inner skeptic really flared up. Oh, I’m sure. It’s a natural reaction. It immediately reminded me of that classic engineering joke. You know, we have 14 competing standards.
Odyssey: This is ridiculous. Let’s create one universal standard that covers all use cases. And the result is that you now have 15 competing standards.
Coda: Exactly. I kept looking for the catch. Like, if I migrate my enterprise team to uv, am I just trading tool fragmentation for proprietary vendor lock-in?
Odyssey: Does Astral now own my project structure?
Coda: That is probably the most critical question an engineering director can ask.
Odyssey: But the architectural choices Astral made point to a deliberate, conscious avoidance of lock-in. How so?
Coda: Because uv tool is rigidly tethered to official Python enhancement proposals, specifically PEP 621, which standardized how project metadata should be declared. So when you run uv init`, it’s not making some weird custom file.
Odyssey: Right. It does not generate a proprietary uv.toml or some obscure configuration format. It creates a completely standard pyproject.toml file. So if a team spends six months using uv and then Astral, say, drastically changes their open source licensing or goes out of business. God forbid.
Coda: Right. But if they do, that team can just uninstall the uv-binary, drop poetry, or even standard pip back into the repository, and the project still functions. Completely. The directory structure is standard. The metadata is standard. Any standard compliant Python tool can parse that exact same pyproject.toml file.
Odyssey: That’s huge. And the respect for the developer goes even deeper than just the file format. When uv modifies your configuration, for example, if you run uv add requests, it utilizes what is called surgical HTML editing. I was actually fascinated by this mechanism.
Coda: Yeah. Because many legacy tools use a really naive serialized and deserialized pass.
Odyssey: Right. They read your entire configuration file into an in-memory data structure, append the new library to the list, and then overwrite the entire file on disk. And the devastating side effect is that it completely obliterates any handcrafted formatting. It strips away the human element entirely.
Coda: Which is so frustrating. If a senior developer leaves a critical comment above a tendency line saying, like, # do not upgrade this package past version 3.0 due to a memory leak. A naive tool will parse the file, drop the comments because they aren’t strictly data, and write back a sanitized comment-free file. Your warning is just gone. But uv doesn’t do that. No. uv parses the file into an abstract syntax tree that actually preserves comments and whitespace.
Odyssey: It patches the exact node in the tree it needs to modify and writes it back, leaving the surrounding human context entirely untouched.
Coda: That is a small detail that saves thousands of hours of frustration in code reviews. Oh, absolutely. But we need to address the lock file. Because the standard pyproject.toml handles the high-level requirements, but the real nightmare for teams has always been reproducible builds. uv generates its own uv.lockfile. How does that avoid the historical pitfalls ofpip freeze`?
Odyssey: Well, the old pip freeze requirements.txt workflow was deeply flawed, because it was inherently platform-specific.
Coda: Right. It just looked at what was installed right then and there.
Odyssey: Exactly. If a developer on an M-series Mac ran pip freeze, the output would include packages and binaries compiled explicitly for Apple Silicon and macOS. And if they committed that text file to version control, and a colleague on a Windows machine pulled the code and tried to install it?
Coda: The build would fail immediately. Pip had no concept of cross-platform awareness. It just took a raw, dumb snapshot of the current machine. The ultimate, it works on my machine, anti-pattern.
Odyssey: Precisely. But from my reading, uv.lock` approaches this dynamically. It’s a universal lock file, right?
Coda: It mathematically evaluates the dependency graph across multiple platforms simultaneously, utilizing environment markers.
Odyssey: That’s exactly right. A single uv.lockfile contains the resolution paths formacOS`, Linux, and Windows, encompassing different architectures like ARM and x86. So a sprawling, geographically distributed team can share that one file. Yes. When a developer on a Windows machine types you sync, the tool doesn’t blindly read the file top to bottom. It inspects the host machine, finds the corresponding resolve path within the log file, and fetches only the correct dependencies for that exact environment.
Coda: It’s environment-aware orchestration. That explains the clean interface and the cross-platform capabilities. But I want to pivot now because we keep mentioning that 100x performance increase. The real magic.
Odyssey: Right. And a clean TOML parser doesn’t explain that magnitude of speed. We need to descend into the underlying systems architecture. How exactly does a package manager achieve speeds that make network I/O look like the bottleneck?
Coda: It requires eliminating entire categories of computational waste that previous tools just accepted as inevitable. We’ve established the first layer, bypassing the Python interpreter startup tax by using compiled Rust.
Odyssey: Right.
Coda: But the deeper optimizations live in how this manages data serialization and caching on the file system. Let’s look at zero-copy deserialization. Yes. The sources specifically highlight a Rust library called rkyv, spelled R-K-Y-V. For the software engineers listening who are used to working with JSON or YAML APIs, what exactly is zero-copy deserialization and why does it matter?
Odyssey: To understand the solution, you have to look at the traditional bottleneck. When pip or Poetry needs to read packaged metadata from its local cache, it’s typically reading a text-based format like JSON. And JSON is basically just a long string of ASCII or UTF-8 characters.
Coda: Right. And to a computer’s CPU, a string of characters is useless for computation. The CPU has to read the string byte by byte, identify the quotation marks, parse the colons, convert string-represented numbers into binary integers, allocate memory on the heap, and finally construct Python dictionary objects. It’s like finding an incredible reference book in the library, but it’s written in ancient Greek. I like where this is going. You can’t just read it.
Odyssey: You have to sit there, translate every single word, and write the English translation onto a brand new piece of paper before you can actually use the information to study. The translation process itself is the bottleneck.
Coda: That is exactly what parsing JSON is. A continuous, heavy translation penalty. Zero-copy deserialization removes the translation step entirely. Wait, entirely?
Odyssey: Entirely. Instead of storing cached metadata as human-readable text, uv stores it via rkyv in a highly specialized, byte-aligned binary format. This format perfectly mirrors the exact layout the data structures require in the computer’s RAM. So when uv needs the data, it doesn’t parse anything. It skips parsing completely.
Coda: It issues a system call to the operating system, specifically Map on Unix systems, instructing the OS to map the physical file on the solid-state drive directly into the program’s virtual memory address space. Oh, wow. You’ve just cast a pointer to that memory address and starts reading the data instantly.
Odyssey: So the data is just there. It operates at O(1) complexity.
Coda: That is brilliant.
Odyssey: It really is. But reading the data fast is only half the battle, right?
Coda: Storing and linking the actual package files, the megabytes of Python code, and compiled C extensions is where developers historically lose gigabytes of hard drive space. Let’s talk about content-addressable storage and the global cache. Historically, if you were, say, a machine learning engineer working on 20 different localized projects, and every project required the Pandas and Torch libraries.
Odyssey: Which are huge libraries. Massive. Your virtual environment tool would physically copy the megabytes of those libraries 20 separate times across your disk. You were burning space and I/O write operations. And uv fundamentally alters this with a centralized cache, typically living at .cache. So when I instruct uv to install Pandas into a new project, it fetches the wheel from the internet once and stores it in that global cache. But how does it get into my project’s virtual environment without being copied?
Coda: It utilizes operating system-level hard links. This requires a quick dive into file system internals. Let’s do it. On a standard file system like ext4 on Linux or APFS on Mac, a file is actually composed of two distinct parts. The metadata directory entry, which is the file name you see, and the underlying physical data blocks on the disk platter, or SSD, known as the inode.
Odyssey: Right. And a traditional shortcut or symlink is a tiny file that simply contains the text path pointing to another file.
Coda: Exactly. And if you delete the original file, the symlink breaks and becomes a dangling point. The symlink just says, hey, go look in this other folder.
Odyssey: Right. But a hard link operates at a lower level. A hard link is a directory reference to the exact same physical internet. So it’s pointing to the actual data blocks. Yes. Yes. You can create 20 hard links in 20 different project directories, and they all point to the exact same physical clusters of data on the drive. To the operating system and to your Python code, it looks and behaves exactly like a distinct standalone file.
Coda: But it consumes zero additional bytes of storage space. Zero. And the linking process takes microseconds because no actual data is being written.
Odyssey: Okay. I have to push back here because any seasoned developer hearing multiple projects sharing the exact same physical file just had a cold shiver run down their spine. Oh, I know exactly what you’re going to ask. Let’s say I have a production service and a messy local testing script, and both are hard linked to the same request library in the global cache.
Coda: Okay. I’m debugging my testing script, and I decide to open the source code of the request library inside my virtual environment and inject a messy print statement to see what’s happening. Because it’s a hard link.
Odyssey: Yeah. Did I just permanently modify the cache and inject a rogue print statement into my production service too?
Coda: It is a sharp, very necessary question, and it’s the exact danger of global link farms. The short answer is yes. If you forcefully open a hard linked file and rewrite the bytes, that modification is reflected across all links pointing to that inode. Oh, that’s it. However, uv’s architecture anticipates this human behavior. The cache is explicitly designed to be thread safe and append only. It operates on the assumption of immutability. The download of packaged versions are immutable artifacts that should never change.
Odyssey: But we know developers break rules. We tinker. How does uv protect us from ourselves?
Coda: It provides deliberate escape hatches. If you are actively developing a package locally or relying on a library with volatile, dynamic metadata, you don’t use the cache blindly. What do you do instead?
Odyssey: You can instruct uv to track specific local directories using the tool.uv.cache-keys configuration in your pyproject.toml. And if you need absolute certainty that a volatile package is fresh, you utilize the tool.uv.reinstall-package directive.
Coda: Which acts as a bypass valve.
Odyssey: Exactly.
Coda: Yeah. It forces uv to completely ignore the hard linked global cache for that specific library. It will re-download and reinstall it entirely from scratch on every run, ensuring perfect isolation.
Odyssey: Okay, that makes sense. Furthermore, uv is incredibly defensive about the physical limitations of hardware. Hard links cannot span across different physical partitions or drives. Oh, right. So if my cache is on my internal SSD and my project is on an external USB drive, a hard link will fail at the OS level.
Coda: Exactly. What happens then?
Odyssey: Does uv just crash?
Coda: No, it degrades gracefully. Oh. uv will first attempt to use copy-on-write reflinks if your file system supports them, like Btrfs on Linux or APFS on macOS, which still deduplicates storage at the block level. And if that also fails. If that fails, it silently and safely falls back to a standard, traditional file copy. The developer experience remains completely uninterrupted. It’s an incredibly resilient piece of systems engineering, so we’ve established that uv fetches data instantly with zero copy and maps it instantly with hard links.
Odyssey: But moving bits on a disk is really only half the equation. Let’s transition to the intellectual core of package management. Fetching files efficiently is totally useless if you don’t know which files to fetch.
Coda: That is the real bottleneck. I want to look at the PubGrub resolver, because dependency resolution isn’t just a basic sorting task.
Odyssey: It is a terrifying mathematical puzzle.
Coda: It is mathematically categorized as NP-complete. Specifically, resolving software dependencies is a variation of the Boolean satisfiability problem, or SAT. For the listener who hasn’t taken an algorithms class in a decade, what does SAT mean when we are talking about Python packages?
Odyssey: It means that as the number of packages, versions, and conditional requirements increases, the computational time required to find a perfectly compatible combination scales exponentially.
Coda: Okay, give me an example. Imagine your project requires package A, version 2.0. Package A requires package B, version greater than 1.5. But you also installed package C, which strictly requires package B to be exactly version 1.2.
Odyssey: So there’s a conflict.
Coda: Right. The resolver has to traverse this massive web of constraints and figure out if there’s any mathematical reality where all conditions are met without contradiction. How did the legacy tools like pip handle this labyrinth?
Odyssey: Historically, pip utilized a sequential backtracking algorithm. It was essentially an educated brute force game of guess and check. Oh, wow.
Coda: Yeah. It would select a version of package A, move down the tree to package B, make a guess, and continue. If it hit a conflict deep in the graph, it would essentially say, oops, that didn’t work, undo its last decision, back up exactly one step, and try the next available version. It’s like trying to solve a massive maze by just walking blindly down a corridor. You hit a dead end, you back up exactly one step, and you try the next left turn.
Odyssey: If that fails, you back up one more step. You learn nothing about the maze itself. You are just exhausting paths. Yes, exactly. And in complex ecosystems like modern machine learning pipelines, which can have hundreds of transitive dependencies, you can wander down millions of dead-end paths. That explains so much.
Coda: This is exactly why pip would notoriously hang for 15 or 20 minutes, violently spinning your CPU, trying to resolve a complex environment before eventually timing out or failing. And uv completely abandons the backtracking approach. Entirely. It implements a Rust version of an algorithm called PubGrub. The sources mention PubGrub originated in 2018, created by Natalie Weisenbaum for Dart’s package manager. What makes PubGrub the gold standard, and how does it escape the guess-and-check trap?
Odyssey: PubGrub implements a strategy called conflict-driven clause learning, or CDCL. Let’s return to your maze analogy. With pip’s backtracking, when you hit a dead end, you just back up.
Coda: Right. With CDCL, when you hit a dead end, you don’t just retreat. You mathematically derive the exact root cause of the failure, and you drop a massive concrete wall blocking that path forever. You write a mathematical rule, an incompatibility clause. Give me a tangible example of an incompatibility clause. Let’s say the solver attempts to combine Flask version 2.0 with SQLAlchemy version 3.0. Deep in their respective dependency trees, they require mutually exclusive versions of a core networking library.
Odyssey: Okay, so they collide. The moment PubGrub detects this collision, it stops. It derives the logic and permanently records a clause stating, the set containing Flask 2.0, SQLAlchemy 3.0, is universally invalid.
Coda: Okay, it wrote down a rule. How does that save time?
Odyssey: Through a mechanism called unit propagation. From that millisecond forward, as the solver continues to search, any future partial solution that even attempts to bring those two versions into the same environment is instantly pruned from the search tree. Wow. The solver doesn’t bother exploring the millions of downstream combinations because it mathematically proved the root premise is poisoned. It dynamically shrinks the size of the maze as it explores it.
Coda: That is profound. And this mathematical derivation also solves one of the most infamously terrible developer experiences, pip’s error messages. Oh, they were notorious. When pip feigns to resolve a backtracking graph, it usually spits out a towering wall of red text that basically translates to, computer says no, I tried a bunch of things and gave up. Because a backtracking algorithm doesn’t actually learn why it failed, it struggles to explain the failure to the user.
Odyssey: PubGrub’s error messaging is fundamentally different. Because of the clauses.
Coda: Right. Because it generates mathematical incompatibility clauses. When uv realizes a graph is unsolvable, it simply walks that derivation tree backward. It outputs a clean, indented, step-by-step logical proof. It tells you exactly what went wrong. It tells you package X requires version 2 of Y. Package Z requires version 3 of Y. Therefore, X and Z are incompatible.
Odyssey: It isolates the exact human error instead of vomiting a stack trace. It treats the developer like an adult. But as I read deeper into the architectural analysis of uv, I found an inherent contradiction here. PubGrub is an incredibly powerful algorithm, but it is fundamentally synchronous. It has to make a decision, evaluate the result, learn from it, and then make the next decision in order.
Coda: That’s true. If the core brain of uv is single-threaded and synchronous, how on earth is it utilizing Rust’s parallel execution to be so fast?
Odyssey: This is where the engineering transcends algorithm design and enters masterful systems orchestration. uv utilizes a highly specialized two-thread concurrency model. I was trying to visualize this when I read the sources. It’s almost like a master chess player sitting at a board. The chess master is the synchronous PubGrub solver. They can only make one move at a time. They have to wait to see the board state before calculating the next move.
Coda: Right. But to make those calculations, they need vast amounts of historical data. In our case, the massive JSON metadata payloads from the PyPI registry on the internet. If the chess master had to physically stand up, walk to the library, read a reference book, and walk back to the board before every single move, the game would take days.
Odyssey: That is essentially what pip does. It blocks the entire process while waiting for network I/O Yes. uv separates the cognitive labor. The main thread runs the synchronous PubGrub solver. But running concurrently alongside it is a background I/O thread powered by the Tokio asynchronous runtime.
Coda: So the Tokio runtime acts as a team of hyperactive assistants for the chess master.
Odyssey: Exactly. While the PubGrub solver is analyzing the current state of the dependency graph, the Tokio runtime is firing off dozens of asynchronous HTTP requests to the internet, speculatively prefetching metadata for packages the solver might need next. Oh, that’s clever. By the time the synchronous solver reaches a node and asks, hey, what are the dependency constraints for NumPy version 1.26?
Coda: The Tokio thread has already downloaded it, parsed it via zero copy, and has it waiting in memory. The core solver almost never blocks on network latency. That sounds incredibly fast, but also terrifying from a memory safety perspective. How so?
Odyssey: Having a background async thread constantly writing data into a shared memory cache at the exact same millisecond that a synchronous thread is trying to read from it, I mean, in C or C++, that is a textbook recipe for a data race. It absolutely is. The program attempts to read partially written memory, it segfaults, it crashes, and you spend three weeks debugging a race condition that only happens one out of a hundred times.
Coda: This specific architectural challenge is exactly why Rust was the only language capable of building a Fav. Rust enforces memory safety at compile time through its ownership model and the Send and Sync traits.
Odyssey: Right. uv utilizes a highly optimized concurrent data structure called a DashMap to share state between the Tokio thread and the solver thread. How does a DashMap prevent the data race without locking up the entire program?
Coda: Because a traditional global mutex lock would just force the threads to wait in line, destroying the parallel speed. A standard mutex locks the entire dictionary. If thread A is writing, thread B must wait, even if it wants to read a completely different key. Dash map mitigates this by sharding the lock. Sharding the lock. It slices the dictionary into multiple independent segments, each with its own localized lock. The Tokio runtime can acquire a lock on shard 3 to insert the metadata for pandas, while the PubGrub solver simultaneously holds a lock on shard 7 to read the metadata for flask.
Odyssey: And the Rust compiler guarantees that a developer at Astral can never accidentally write code that bypasses those locks. Yes. It is what the Rust community calls fearless concurrency. If a programmer attempts to pass an unprotected, mutable reference of the cache across thread boundaries, the Rust compiler simply halts and refuses to compile the binary. The safety is mathematically proven before the software ever ships to users.
Coda: Exactly. It’s an accumulation of brilliant decisions, and I noticed one more micro-optimization that just blew my mind. The version packing. Yes. When the solver is churning through these dependency graphs, it has to compare version numbers millions of times. You and I read a version as a string, 1.2.3. But comparing strings is computationally expensive, because the CPU has to compare them character by character in memory. How does uv optimize this?
Odyssey: They pack the versions into integers. uv recognizes that over 90% of real-world Python packages use standard semantic versioning, major, minor, and patch numbers.
Coda: Right. Instead of storing them as strings, uv mathematically packs those three numbers into a single 64-bit integer, a u64. So it transforms a slow, multi-byte string comparison into a simple number comparison.
Odyssey: Exactly. Comparing two 64-bit integers requires a single primitive CPU instruction. It takes less than a nanosecond. When you multiply that micro-optimization across the millions of version comparisons required during a complex PubGrub resolution, it compounds into massive visible time savings.
Coda: Okay. So we have a mathematically rigorous, highly concurrent solver racing through memory. But all of this mathematical profession assumes that the rules of the game are static. What happens when the rules change depending on whose computer you are looking at?
Odyssey: Because the Python ecosystem is notoriously chaotic, a single package can have completely contradictory requirements based on the operating system or the underlying Python version. It’s a mess. How does uv handle that platform-specific chaos within a universal lock file?
Coda: This is perhaps the most computationally intensive feature uv provides, the forking resolver. Let’s take a real-world troublemaker like NumPy. The metadata for NumPy might declare that if you are installing it on Python 3.11, it strictly requires version 2.0. But if you are installing it on legacy Python 3.0, it requires version 1.26. A naive solver would look at those contradictory rules, realize it cannot install both version 2.0 and version 1.26 simultaneously, declare the graph unresolvable, and crash.
Odyssey: Right. To prevent that, when uv solver encounters requirements that diverge based on environment markers, it literally splits the resolution process into parallel, independent branches. It forks reality. It creates alternate universes. Universe A, where the machine runs Python 3.11, and Universe B, where the machine runs Python 3.1.0.
Coda: Precisely. It traverses both universes simultaneously using sophisticated data structures called algebraic decision diagrams, or ADDs. Algebraic decision diagrams. Yes. An ADD allows the solver to represent these diverging logical paths without experiencing combinatorial explosion. It solves the graph for Universe A, it solves the graph for Universe B, and then it merges those distinct conflict-free realities back together into the single uv.lock` file.
Odyssey: So the uv.lockfile isn't just a flat list of dependencies. It's a multidimensional map of every possible compatible environment state. It's a map. And this is whyuv sync is so blisteringly fast when a developer actually runs it. When you pull the code on your laptop and run uv sync, your computer doesn't have to perform any of the heavy SAT`-solving math or reality forking. Because it’s already done.
Coda: Exactly. Your local instance of you simply evaluates its own environment. I am an ARM64 Mac running Python 3.11 and uses that identity to trace the pre-solved optimized paths through the algebraic decision diagram in the log file. It’s a simple, instantaneous graph traversal. The heavy lifting was entirely front-loaded by the person who originally ran uv lock`. But to make that initial heavy lifting fast, the set ever has to know what decisions to prioritize.
Odyssey: Oh, prioritization is key.
Coda: Right, because if you have 200 dependencies, you can’t just pick one at random to start with. What is uv’s heuristic for attacking the graph?
Odyssey: uv employs a highly opinionated prioritization strategy. When examining an unresolved pool of packages, it forces decisions in a specific order. At the absolute top of the hierarchy are direct URL dependencies. Makes sense.
Coda: Yeah, if your pyproject.toml explicitly points to a .oche file on a local file system or a specific commit hash on GitHub, Uv resolves that instantly. There is no version negotiation required. The exact artifact is mandated. That makes perfect sense. What’s next?
Odyssey: Next are exact pins. If you require Django equals 4.2.5, the solver locks it immediately.
Coda: But the true genius is how it handles loose version ranges. Uv actively monitors the resolution process and tracks the packages that cause the most incompatibility clauses to be generated. It tracks the troublemakers. Identifies the bottlenecks in real time. Yes. If Uv detects that a specific package has triggered five different conflict backtracks, it marks that package as highly conflicting. It forcefully promotes its priority, pulling it to the absolute front of the line to be resolved immediately.
Odyssey: Wait, why does resolving the most difficult packages first speed up the process?
Coda: Because the troublemakers have the most restrictive constraints. If you force the solver to establish the boundaries of the most difficult packages at the very beginning of the process, you drastically narrow the mathematical search space for all the flexible, easy packages later on. Oh, I see. You prevent a scenario where the solver makes a thousand easy decisions, only to hit a highly restrictive package at the end that invalidates all 1,000 prior choices.
Odyssey: It forces the hardest constraints up front so the rest of the graph falls into place. It’s masterfully designed. But we need to look at the shadows. Every piece of software makes assumptions. And when those assumptions meet the real world, things break. Inevitably. If I’m a distinguished engineer evaluating for a massive enterprise migration, what are the blind spots?
Coda: What are the edge cases that are going to trigger pager alerts at 3 a.m.?
Odyssey: The most dangerous blind spot stems directly from the assumption DU uses to achieve its speed, the metadata consistency assumption. Let’s unpack metadata consistency. When a maintainer uploads a package to PyPI, they generally upload two artifacts, a pre-compiled wheel, which is basically a ready-to-install zip file, and a source distribution, which is the raw C or Python code that needs to be compiled on the end user’s machine. Correct. To resolve dependencies concurrently at lightning speed, uv assumes that the metadata, specifically the requires list of dependencies, is identical across all wheels at all source distributions for a given version of a package.
Coda: So it only checks once.
Odyssey: Right. If it reads the metadata from a Linux wheel for NumPy 2.0, it assumes the macOS wheel and the source distribution have the exact same requirements. Meaning uv only has to make one network request to PyPI, fetch one piece of metadata, and confidently apply that knowledge across its entire corking resolver. Yes. But knowing the Python ecosystem, is that assumption actually enforced by any standard?
Coda: It is not enforced at all.
Odyssey: It is entirely possible and historically common for a package author to write dynamic build scripts, like a setup.py, that execute arbitrary code to determine dependencies at install time. An author might create a source distribution that, when compiled on the user’s server, suddenly demands different undocumented dependencies than the pre-built wheel advertised. That sounds like a ticking time bomb. What happens when uv counters a dynamic package like that?
Coda: uv’s sound dependency locking fundamentally breaks. Imagine uv resolves your project perfectly on your laptop. It reads the wheel metadata, assumes package A requires package B, and writes that to uv.lock. Sounds good so far. But during your production deployment on a Linux server, uv` is forced to build package A from a source distribution. The dynamic script runs, and suddenly demands package C-UV will look at the lock file, realize package C isn’t authorized, and fail the installation.
Odyssey: It causes a late-stage deployment error.
Coda: Which is the most expensive and terrifying kind of error. Why doesn’t the Python Packaging Authority just ban dynamic metadata and force everyone to be consistent?
Odyssey: They have tried. There have been numerous PPP proposals attempting to enforce static, consistent metadata.
Coda: But the sheer legacy complexity of the ecosystem, especially regarding scientific computing packages with complex C++ compiler requirements, makes it difficult to enforce retroactively.
Odyssey: Right. However, the ecosystem is rapidly aligning. Major historical offenders, like Torch and TensorFlow, have modernized their tooling to emit consistent metadata.
Coda: It is becoming an edge case, but for an enterprise engineer, it is a critical vulnerability to be aware of when dealing with obscure, unmaintained internal libraries.
Odyssey: That is a crucial warning. The sources also mention another philosophical friction point regarding requires Python upper bounds. Ah, yes.
Coda: This is a very specific metadata tag where a package author declares what versions of Python their library supports. For example, they might write requires Python 3.9 4.0. But I read that uv intentionally ignores that upper bound 4.0.
Odyssey: It does. I have to push back hard on this. If I maintain an open source library and I explicitly document that my code will break on Python 4.0, why does uv presume to know better than me?
Coda: Why does it aggressively override my explicit constraints?
Odyssey: It is a deliberate choice favoring ecosystem pragmatism over strict metadata adherence. Experience over the last decade has shown that package authors frequently add upper bounds preemptively out of an abundance of caution, not empirical evidence.
Coda: So they’re just guessing. Essentially, yes. They add 4.0 or 3.13 simply because those versions of Python don’t exist yet and they haven’t run their unit tests against them. Ah, and if every major package in the ecosystem preemptively bans future Python releases, what happens when a new beta version of Python actually comes out?
Odyssey: The entire ecosystem paralyzes. No one can install anything to test the new beta because the dependency resolver strictly honors the arbitrary upper bounds. It creates a gridlock where nothing can be updated until thousands of maintainers manually edit their metadata and push new releases. uv recognized this gridlock and decided to drop the upper bound entirely to allow the ecosystem to keep moving forward. But dropping it must cause actual breaks, right?
Coda: Not every upper bound is preemptive caution.
Odyssey: Absolutely. Packages that rely heavily on the internal version-dependent C API of CPython like NumPy or cryptography often experience catastrophic compilation failures when run on newer Python minor versions.
Coda: Right. When uv bypasses their legitimate upper bound, the developer is hit with a nasty C compiler error during installation. uv tries to mitigate this by splitting resolution markers dynamically when it detects compilation failures, but it remains a highly controversial pragmatic compromise. It’s the classic tradeoff between stricter correctness and usability. Now, there is one massive elephant in the room we have to address before we talk about enterprise rollout. Let me guess. Conda.
Odyssey: Yes. For anyone working in data science, machine learning, or bioinformatics, you are probably screaming at your audio player right now. What about Conda?
Coda: How does uv compare to Conda, and can a data science team just rip out Conda and replace it with you?
Odyssey: The comparison must be heavily contextualized. uv is strictly, exclusively, a Python package manager.
Coda: It is designed to pull Python wheels and source distributions from PyPI. Conda is a general-purpose environment and system package manager. Meaning Conda reaches far below the Python layer. Yes. Conda manages arbitrary C and C++, plus binaries, Fortran compilers, Rust toolchains, and incredibly complex system-level dependencies like NVIDIA CUDA drivers for GPU acceleration. So it’s much broader.
Odyssey: Exactly. If your data science pipeline relies on Conda Forge to seamlessly install specialized C++ graphing libraries or system-level audio encoders so your developers don’t have to compile them from scratch, uv cannot replace that. uv assumes that the underlying operating system and the system-level libraries are already configured and present. So if I am building a standard web application backend using FastAPI or Django, moving to uv is an absolute no-brainer. 100%. But if I am provisioning bare metal servers for deep learning and I need 10 different versions of C++ drivers managed alongside my Python code, Conda remains structurally necessary.
Coda: Exactly. Although we are seeing sophisticated enterprise teams adopting a hybrid approach, they use Conda purely at the infrastructure layer to provision the rigid system environment and the CUDA drivers. And then they inject off into that Conda environment to manage the rapidly iterating Python dependencies at lightning speed. Leveraging the strengths of both.
Odyssey: Okay. Let’s look at the big picture. We are in April 2026. The adoption metrics are undeniable. uv has hit 126 million monthly downloads, completely surpassing Poetry and the Older Guard. It’s taken over. If I am an engineering director and I want to orchestrate a migration for a 500-person engineering department, how do I actually execute that without grinding feature development to a halt?
Coda: Let’s start with Docker and CI/CD because that’s where the money is spent. Deploying up inside Docker is a transformative architectural win. Because Uv is a standalone, statically compiled Rust binary, it requires absolutely zero underlying dependencies to run. Wait, really?
Odyssey: Yes. You can literally copy the Uv executable into an empty scratch Docker-based image, an image that doesn’t even have an operating system shell or a Python interpreter installed yet. Wait, if the Docker container has no Python interpreter, how does Uv run the Python code?
Coda: Because Uv can fetch and install the interpreter dynamically. You invoke off Python install inside your Docker file. It pulls down a pristine pre-compiled Python interpreter, sets up the virtual environment, and installs your packages.
Odyssey: That’s incredible. This eliminates the need to rely on heavy, bloated base images like Python.3.12 bullseye. It shrinks your container sizes drastically, which reduces cold start times in serverless environments and vastly minimizes the security attack surface of your containers.
Coda: That is massive for cloud infrastructure costs. What about managing large, multi-project repositories?
Odyssey: For massive enterprise monorepos, Uv implements a feature directly inspired by Cargo, Rust’s Package Manager, workspaces. How does that work?
Coda: In a sprawling enterprise, you might have a single Git repository containing a core data processing library, three different consumer-facing web APIs, and a dozen internal utility scripts. Historically, ensuring that the web API didn’t accidentally use a version of Pydantic that was incompatible with the core library was a nightmare of manual version pinning. You’d have a dozen different requirements.txt files drifting out of sync.
Odyssey: Exactly. A Uv workspace allows you to link all of those internal Python packages together under a single, unified Uv.lock file sitting at the root of the repository. Oh, that is so clean. If the team maintaining the core library upgrades a shared dependency, the workspace lock file forces the resolver to ensure that every single web API and utility script in the monorepo is tested and mathematically compatible with that new version. It enforces ecosystem discipline at a scale Python natively struggled with.
Coda: It brings systems-level rigor to a dynamic language. But I want to talk about the business reality of this tool. The open-source landscape shifted dramatically recently. You’re talking about March 2026. Yes. Astral, the company that built of the rough linter and the type checker, was acquired by OpenAI. What does that mean for the enterprise engineer placing their bets on uv?
Odyssey: It’s a defining watershed moment. It signals that major AI research organizations no longer view Python tooling as a peripheral community effort. They view it as mission-critical, strategic AI infrastructure. Because Python is the lingua franca of artificial intelligence.
Coda: Exactly. The faster Python development and deployment becomes, the faster AI models can be iterated and scaled. OpenAI acquired Astral to secure and accelerate the foundation of their own development pipelines. But whenever a massive corporation acquires critical open-source infrastructure, the community gets nervous. If I tie my company’s entire build system to Av, do I need to worry about the rug being pulled?
Odyssey: Will OpenAI start gating premium features or dictating the open-source roadmap?
Coda: It is the eternal double-edged sword of open-source acquisitions. The immediate benefit is financial security. uv is backed by virtually unlimited resources and will not suffer from maintainer burnout.
Odyssey: But the apprehension is valid. The defense against that apprehension brings us back to the architectural choices we discussed in the beginning. The reliance on PD standards?
Coda: Exactly.
Odyssey: Exactly. Because Uv outputs standard pyproject.toml files and relies on standard virtual environment layouts, the exit cost is phenomenally low.
Coda: Yeah. If the corporate direction of Astral shifts in a way the community rejects, you are not trapped in a proprietary database. You still have a standard Python project. You can migrate back to pip or another standard compliant tool over a weekend. The architecture inherently protects you from severe vendor lock-in. That provides serious peace of mind for a CTO. So give me the practical three-step adoption framework. If I want my team moving to Uv by next week, how do I do it safely?
Odyssey: You never do a Big Bang rewrite. You execute a phased rollout. Step one, target your CI/CD pipelines. Do not change a single configuration file in your project. Simply replace the command pip install with uv pip install in your GitHub Actions or Jenkins scripts. It requires zero developer retraining, carries virtually zero risk, and will instantly slice your build times down by an order of magnitude. You secure the massive performance wins silently in the background.
Coda: What is step two?
Odyssey: Step two, transition the developer experience for global tools. Have your team deprecate pipx and begin using uv tool runoruvxfor their daily workflows. When they need to run black to format code orPyTestto run test suites, executing it throughuvxis faster and begins to build muscle memory with theuvcommand line interface. And the final step. Step three, the structural refactor. For any brand new microservices, establish a strict policy to bootstrap them exclusively usinguv init, leaning fully into the pyproject.toml standard.
Coda: For legacy projects, begin the process of translating those old requirements.txt files into native TOML dependencies. Commit the uv.lockfile to version control and mandate that developers useuv sync to hydrate their local environment. Step one, transparent speed in CI. Step two, CLI familiarity. Step three, total architectural alignment. It’s a deeply pragmatic roadmap. It turns environment management from a terrifying, fragile chore into a silent, instantaneous background utility. It eliminates the friction between having an idea and executing it.
Odyssey: You stop fighting the build system and return to writing actual logic.
Coda: Which is the entire point of software engineering. To wrap this up, the sheer scale of what Astral has accomplished with uvN is breathtaking.
Odyssey: It really is an engineering marvel. By discarding the legacy Python-based toolchain and rewriting the core infrastructure and statically compiled Rust, they eliminated the interpreter startup tax. They introduced zero-copy deserialization with ERK-uv, deployed a space-saving global cache backed by hard links, and solved the NP-complete dependency nightmare using the mathematically rigorous PubGrub CDCL algorithm, all orchestrated by a memory-safe concurrent Tokio runtime.
Coda: It is a masterclass in applying aggressive systems engineering to a fundamentally chaotic ecosystem. It truly is. And I want to leave you, the listener, with a slightly provocative thought to mull over. Oh, I’m curious. We’ve just spent an hour exploring how Python, a dynamic, highly interpreted, highly flexible language burst in the 1990s, is currently being kept globally competitive by strapping it to the back of Rust, a strict, statically typed, memory-safe systems language from the 2010s.
Odyssey: Yeah, that’s true. We are rapidly entering a paradigm where the primary syntax developers write in Python is becoming fundamentally divorced from the language used to build the ecosystem’s infrastructure. It creates a fascinating technical dichotomy. The interface is Pythonic, but the engine is Rust.
Coda: Exactly. And if the tooling required to manage Python has to be written in an entirely different, harder language just to be fast and safe enough for enterprise scale, what does that say about the ultimate trajectory and limits of Python itself?
Odyssey: That’s a deep question. Are we destined to keep wrapping Python in increasingly complex layers of Rust armor just to keep it viable for the next decade of AI development?
Coda: It is a profound shift in the language’s identity. It forces us to ask whether Python is still a standalone ecosystem or if it is evolving into a scripting frontend for high-performance compiled backends.
Odyssey: Absolutely. If you want to experience this speed firsthand and try bootstrapping your next microservice with zero friction, head over to the official Astral documentation. It will fundamentally change your expectations of developer tooling.
Coda: It really will. And, you know, thinking back to our ridiculous car dealership, it turns out you never needed that massive heavy brass key ring with a dozen different keys to start your engine. You just needed the universal smart key all along. Thanks for joining us on this deep dive.