Tech | Mastering Python's Object Model and Performance Traps
An episode on Python objects, dynamic dispatch, descriptors, memory layout, and performance tradeoffs in real systems.
Episode text
Transcript
Overview
Python object model, dynamic dispatch, descriptors, memory layout, and performance tradeoffs.
Transcript
Coda: Welcome back to the Deep Dive. Today we’re on a mission, a really foundational one for anyone who wants to go from just, you know, writing Python that works to writing code that’s genuinely Pythonic.
Odyssey: Yeah, code that’s performant and robust.
Coda: Exactly. We are pulling back the curtain on the language itself.
Odyssey: That’s right. If you’re an engineering manager, maybe an instructor, and you have to get new engineers up to speed on Python, well, this Deep Dive is for you. It’s your shortcut.
Coda: So what are we doing exactly?
Odyssey: We’re basically translating the core architecture of Python, its data model, from the official language reference, which can be a bit dense. A bit dense is an understatement.
Coda: Right. And from some foundational training materials, and we’re turning it all into clear first principles engineering knowledge. The goal here is to get past just the syntax, right?
Odyssey: Exactly. We want to master the, let’s call them the immutable laws that govern every single thing that happens in Python. And it all centers on what we call the object triad.
Coda: And that’s so critical. We’re trying to help you explain and avoid those, you know, those subtle bugs and performance issues that trip up junior engineers for months.
Odyssey: Yeah. We need to stop treating Python like this black box that just magically does things. And start understanding it as a really precisely engineered system. So today we’re focusing on what, four concepts?
Coda: First, that object triad we mentioned, identity, type, and value.
Odyssey: Okay. Then the critical difference between identity and equality.
Coda: Yeah. You know, is versus, that leads right into aliasing. The source of so much pain.
Odyssey: It really is. Third, we’ll look at how namespaces organize everything. And finally, we’ll cover the rules for deterministic resource management. Basically, how to clean up after yourself reliably.
Coda: Right. We want to give you the context to explain to your team why some code is fast and some is slow, or why one little change can cause a huge side effect somewhere else.
Odyssey: This is all about the architectural intent.
Coda: That’s the perfect way to put it. All right. So let’s start at the absolute beginning. The one fundamental building block of Python. Everything is an object. Everything. Yes. That is the core abstraction. Every single piece of data, every relationship between data, it’s all represented by objects. So when you say everything, you mean like the number five. The integer five is an object. A string is an object. Mm-hmm. But it goes deeper. A class definition is an object.
Odyssey: Yeah. A function call creates objects. objects, the actual frame objects that represent the program running right now. Those are objects too.
Coda: Okay. And you said every single one of these objects has three pillars. So let’s do pillar one. Identity. Identity. This is the object’s unique identifier. You can think of it as its physical address in memory. Where it lives.
Odyssey: Exactly. And once that object is created and given an identity, that ID never, ever changes for the entire life of that object. It’s permanent. So if it’s a memory address, how do we actually see it?
Coda: I mean, Python is supposed to hide memory management from us, right?
Odyssey: It does. And it does that with the built-in id function. It gives you back an integer that represents that identity. An integer, not the raw memory address itself.
Coda: Right. Now, in CPython, which is what most people use, that integer usually is the memory address.
Odyssey: But the language spec says you should only ever treat it as a unique, unchanging number. An opaque identifier. So we shouldn’t really be using id to check if two things are the same object. No. The real tool for that is operator. If you say x is y and it returns two with 100% certainty, that x and y are just two different names for the exact same object in the same spot in memory.
Coda: Got it.
Odyssey: Okay. Pillar two. Type. If identity is the address, you said type is the blueprint.
Coda: Precisely. The type of an object tells you two critical things. First, what kind of data it is. Like an integer or a list.
Odyssey: Right. And second, and this is the important part, what operations it supports. Can you ask for its length with len?
Coda: Can you loop over it?
Odyssey: Is it callable, like a function?
Coda: The type defines its capabilities. And just like identity, the type is fixed once the object is created.
Odyssey: Absolutely. You can’t just take a list object and decide to turn it into an integer while keeping the same identity.
Coda: That’s not how it works. You use the type function to see its type. And the type itself is an object.
Odyssey: Which is a fun little recursive fact, yes. Types are objects too. So yeah, if identity is the street address, type is the blueprint for the building at that address. Is it a house, a store, a factory?
Coda: Perfect. So that brings us to the last pillar, pillar three. Value. This is what the object actually holds.
Odyssey: Right. And this is where the Python world splits into two. And it’s probably the most important distinction in the entire language. Mutability versus immutability. Yes. And I would say 90% of subtle Python bugs come from misunderstanding this. The value of some objects, they can be changed after they’re created. We call those mutable. Lists, dictionaries, sets.
Coda: Exactly. The others have a value that’s fixed forever. They are immutable. Numbers, strings, tuples. Correct. But let’s dig into that definition of immutability, especially with containers. Because this is where new engineers get really confused.
Odyssey: Okay. Yeah. So if I have a tuple, which is immutable, and inside that tuple, I stick a list, which is mutable. Classic case. The tuple is still considered immutable. But why? I mean, I can change the list inside it so the overall value that I see has changed.
Coda: That is an excellent point. And it forces us to be really precise with our language, just like the Python spec is. Immutability is a guarantee about the container’s direct contents. Meaning?
Odyssey: Meaning it’s a guarantee about the collection of object identities that it holds a reference to.
Coda: Okay. So let’s use an analogy. If the tuple is like an address book, it holds the permanent, unchangeable address of that list object. Perfect analogy. The reference itself, the pointer to that specific list object’s ID, is fixed. You can’t make the tuple point to a different list object or add a new object to the tuple.
Odyssey: But the thing living at that address, the list itself, can be renovated.
Coda: Exactly. The list can be modified internally. The language reference is very clear. The tuple retains the same collection of object identities, and that’s what makes it immutable. You’re guaranteeing the container’s structure, not the state of every single thing nested inside it.
Odyssey: That is a really important distinction.
Coda: Okay. So we have our triad. Let’s put it into practice and talk about the difference between is and et quotes. You called this physics versus philosophy. I did. Is the physics check. Are these two names pointing to the exact same chunk of memory?
Odyssey: It’s cheap, it’s fast, it’s totally unambiguous. Fantastic. Is the philosophy. Do these two objects represent the same abstract value?
Coda: This check relies on the object implementing a special method, EQ, to compare their contents. So you could have two different list objects, lista and list b.
Odyssey: Right. And they both contain, say, the numbers 1, 2, lista. Is list gully would be false?
Coda: Because they’re two separate objects, two different houses built from the same blueprint. Correct. But list a meal would be true because their values are equivalent.
Odyssey: Okay. Let’s use a classic example to show what this means for mutability. We’ll start with an immutable type. Let’s say I have an integer, a 8, 10. What is actually happening under the hood when I run a plus 5?
Coda: Well, someone coming from, say, C++ or Java might think that Python just goes to the memory spot for a top and changes the 10 to a 15. But that’s completely wrong for immutable types. Fundamentally wrong. Because integers are immutable, that original object holding the value 10 cannot be changed. So Python does this little three-step dance.
Odyssey: Okay. What are the steps?
Coda: First, it computes the result, which is 15. Second, it creates a brand new integer object somewhere else in memory with the value 15. And third. It rebinds the name A to point to this new object. The identity of A has completely changed. If you check diet A, before and after, you get two different numbers. And this has huge consequences when aliasing is involved. So if I had another name, B, and I did BA when it was 10, now A points to 15, what happened to B?
Odyssey: Nothing at all. And that is the safety and predictability of immutable types. The name A just changed where it was pointing. The name B is completely unaffected. It’s still pointing at that original object that holds the value 10. The names are just independent labels. Changing which object one label points to doesn’t affect the other.
Coda: Exactly. Now let’s wade into the danger zone. Mutable types. Specifically lists. All right. Let’s start with a non-in-place operation. I have a 10. Then I run a plus 5.
Odyssey: Okay. So this is list concatenation. And the really critical thing here is that you are using the assignment operator. So even though the list is mutable, that makes Python act like it was dealing with an immutable type. In a way, yes. The expression on the right, a plus 5, gets calculated first. That produces a result, 10, 5. But because the ODE is there, Python sees this as a name reassignment. So it makes a new list.
Coda: It creates a new list object in memory, 10, 5, and then rebinds the name A to this new object’s identity. The original list object, 10, is now floating in space, waiting to be garbage collected. And if my friend B was pointing to that original 10. Then B is still pointing to 10. It saw no change.
Odyssey: But the whole world changes if we use an in-place version like O.ipen 5 or the augmented assignment of plus equal 5. It’s a completely different universe.
Coda: This is the difference between asking Python to build a new house versus asking it to renovate the existing one. I like that. Operations like append or plus on a list, modify the object in place. The identity of the object it points to does not change. The memory address is the same. You’ve just changed the contents at that address. And this right here is the concept of aliasing.
Odyssey: This is what causes junior engineers hours and hours of debugging pain.
Coda: It really is. So let’s set it up. We have A equals 10. Then we say B equals. So now both A and B are just names, labels, pointing to the exact same list object in memory. They are aliases. They share a wallet. There is only one list object. So when you run an 8.ipen 5, you’re modifying that single shared object.
Odyssey: Which means when I go and look at B. It immediately sees a change. No. B is now 10.5. Because there was only ever one list.
Coda: This isn’t a bug. It’s a fundamental performance critical feature of Python’s object model. You need it to pass big data structures around efficiently without copying them all the time.
Odyssey: Okay. Let’s cement this with the classic failure case. The bad matrix bug.
Coda: This is the perfect cautionary tale.
Odyssey: It is. The bad matrix bug happens when a junior engineer tries to create, say, a 3x3 grid of zeros. And they do it like this. Matrix equals 0, 3, 3. It looks so clever. It looks like it should work. You’re making a row of three zeros and then making three copies of that row.
Coda: That’s what you think you’re doing. But what you’re actually doing is creating one inner list object, 0, 0, 0, and then creating an outer list that contains three references to that single inner list. So if we were to actually check idmatrix 0, idmatrix 1, and idmatrix 2, we’d find they’re all the exact same number.
Odyssey: Precisely. They are three aliases for the same object.
Coda: So the moment you try to change one element, say, matrix 100 equals 1. You’ve modified the single shared list, and it looks like you’ve changed the first element of every single row simultaneously. You have. And suddenly your matrix is 1, 0, 0, 1, 0, 1, 0, 1, 0, which is almost never what you wanted.
Odyssey: So what’s the good matrix solution?
Coda: You have to explicitly create three different inner list objects. The pythonic way is with a list comprehension. Matrix equals 0, 3 for inrange 3. That loop runs three times, and each time it creates a brand new list object with a unique identity. The lesson here for the team is profound. When you’re dealing with mutable objects, aliasing is a constant risk. If you’re going to modify something, you better be sure you’re the only one pointing to it, or you need to explicitly make a copy.
Odyssey: Yes. Using slicing like new list, old list, or the poppy module. Be deliberate.
Coda: Okay, before we leave identity, we have to talk about one more thing. The integer caching. Gotcha. This one seems to break all the rules we just set up.
Odyssey: It does feel that way. The question is, why would x 100 in minute, and then y in 100 on a separate line, sometimes result in x is y being true?
Coda: We just said immutable assignments create new objects.
Odyssey: Right. So it should be false. And it would be, except for a very specific optimization in CPython. It’s a performance hack.
Coda: Well, it’s the hack. CPython preallocates a pool of commonly used small immutable objects when the interpreter starts up, specifically integers from medical 5 to 256. Ah, so when I say x equals 100, CPython doesn’t create a new object. It just says, oh, I already have 100 object in my cache. I’ll just point x to that.
Odyssey: Exactly. And when you then say y 100, it does the same thing. It just points y to that same preexisting cached object.
Coda: Right. So x is y becomes true. But if I use a bigger number, like 1,000. 1,000 is outside that cache range. So for x equals 1,000, CPython will create a new integer object. And for y equals 1,000, it’ll create a second, totally separate new integer object. In that case, x is y is false, even though x of y is true.
Odyssey: So the danger here, what you have to tell your team, is that relying on 100 is 100 being true is writing incredibly fragile code. It’s the definition fragile code.
Coda: Yeah. Because you are relying on a CPython-specific implementation detail. It’s not guaranteed by the language itself. If you run that code on PyPy or Jython, it might fail. It very well might. The optimization might not be there. The rule you have to teach is simple. Always use for comparing values. Only use is when you genuinely specifically need to know if two names refer to the exact same object in memory.
Odyssey: Okay, that’s clear. Let’s move from these abstract concepts to the concrete types we use every day. The documentation lays out this whole type hierarchy.
Coda: It does.
Odyssey: Yeah. And it’s important to realize it’s not just about, you know, lists and decks. It also defines the internal machinery of the interpreter. Things you don’t often touch directly, like code objects, frame objects, slice objects. Before we get to the data structures, let’s quickly cover those critical singleton objects.
Coda: Right. The objects that exist only once. There’s none, of course, which means absence of value and is always false in a Boolean check. There’s ellipsis, which you get by typing three dots.
Odyssey: Yeah. Often used in things like NumPy or type hinting, it evaluates to true. And then there’s the one that’s more of an internal signal, not implemented. Not implemented is a special sentinel. It’s what methods, especially numeric ones or rich comparison like eek, return when they don’t know how to handle the operation with the given type. So it’s a signal back to the interpreter saying, I can’t do this. Maybe you should try asking the other guy.
Coda: That’s a great way to put it. It’s an internal handshake.
Odyssey: Yeah. The important update here for engineers is that as of Python 3.14, if you try to use not implemented in an us statement, it will raise a type error. They’re locking it down saying this is not for general purpose logic.
Coda: Exactly.
Odyssey: Okay. So let’s get to the data types, starting with numbers. The Python int type is. It’s mathematically pure.
Coda: That’s a huge design choice. And all numeric types. So int, float, complex, they’re all immutable. All immutable. That purity of the int type means it has unlimited range. It’s only limited by your computer’s memory.
Odyssey: This is Python’s built-in Bignum support. You don’t have to worry about integer overflow like you do in C or Java. Correct. When a C integer hits its 32-bit or 64-bit limit, it silently wraps around, which is a source of terrible bugs. Python avoids that entirely by handling the complexity internally. It might be a tiny bit slower for simple math, but it guarantees correctness, which is a core part of the language’s philosophy.
Coda: And what about floating point numbers?
Odyssey: Float objects in Python map directly to the machine’s 64-bit double precision type.
Coda: So they have the same limitations as any other language using hardware floats. Yes. Same precision issues. Same potential for overflow.
Odyssey: But the interesting design choice is that Python avoids single precision 32-bit floats. Why is that?
Coda: Seems like you could save memory. You could, but the overhead of just having a Python object at all is usually more than the four bytes you’d save. So for simplicity and consistency, they just stick with double precision everywhere.
Odyssey: Okay. Let’s move on to sequences. These are finite ordered sets, indexed from zero. And again, we have that big mutability divide. We do. In the immutable corner, we have strings.
Coda: Which are sequences of Unicode code points. There’s no separate char type in Python.
Odyssey: Right. Then we have topos, which are just comma separated collections of other objects. And finally, bytes, which are immutable arrays of 8-bit integers. And in the mutable corner, we have the workhorses. Lists, of course. They’re collections of arbitrary objects that you can change a sign to, insert into, delete from. And by array, which is just the mutable version of bytes, perfect for when you’re working with binary data that you need to modify in place.
Coda: And finally, we get to sets and mappings. The entire design of these is governed by one critical performance rule. Hacibility. Explain what that means. It’s absolutely essential to how they work. Sets are unordered bags of unique things. And dictionaries are key value pairs. To make looking things up in them incredibly fast, they’re both built on hash tables. And for a hash table to work, the items you put in it, the set elements or the dictionary keys must be hashable.
Odyssey: Right. And hashable means two things. One, the object has to have a hash value that never changes during its lifetime. And two, it has to have a way to be compared for equality. That eek method again. Why is that constant hash value so important?
Coda: Performance. To find something, Python computes its hash, which immediately tells it which bucket to look in. It’s a massive shortcut. If the object’s value, and therefore its hash, could change while it was already in the dictionary. Python would look in the wrong bucket and never find it again.
Odyssey: Exactly. It would be lost forever. And that is why mutable things like lists, dictionaries, and other sets cannot be used as dictionary keys or set elements. Their value can change, so their hash can change. They are unhashable.
Coda: This is why we have the two set types, right?
Odyssey: The mutable set. And the immutable frozen set. Since a frozen set is immutable, its hash is stable, so you can use a frozen set as a key in a dictionary or as an element inside another set. Makes sense. And for dictionaries, one last modern feature to mention. Oh yeah, a big one. Since Python 3.7, dictionaries are guaranteed to preserve insertion order.
Coda: Which used to be a huge pain point. People would use order dict all the time. They did. Now it’s built in. If you replace a key’s value, it stays in the same position. But if you delete a key and then add it back, it moves to the end. That guarantee is incredibly useful.
Odyssey: Okay. We know what objects are. We know their types. Now where do the names that point to them actually live?
Coda: This brings us to namespaces.
Odyssey: Right. A namespace, conceptually, is just a mapping. It’s usually a dictionary that connects names, which are strings, like your variable names, to the actual objects in memory. And they are everywhere, defining the scope of everything. Everywhere. You have the module namespace, which you see when you call globals. When a function is running, it has its own local namespace, locals. And for object-oriented programming, you have class namespaces and instance namespaces.
Coda: Okay. Let’s use a concrete example. I define a class user. I give it a class variable, species evil human, and a method get species. Where do those two things live?
Odyssey: They live in the class namespace.
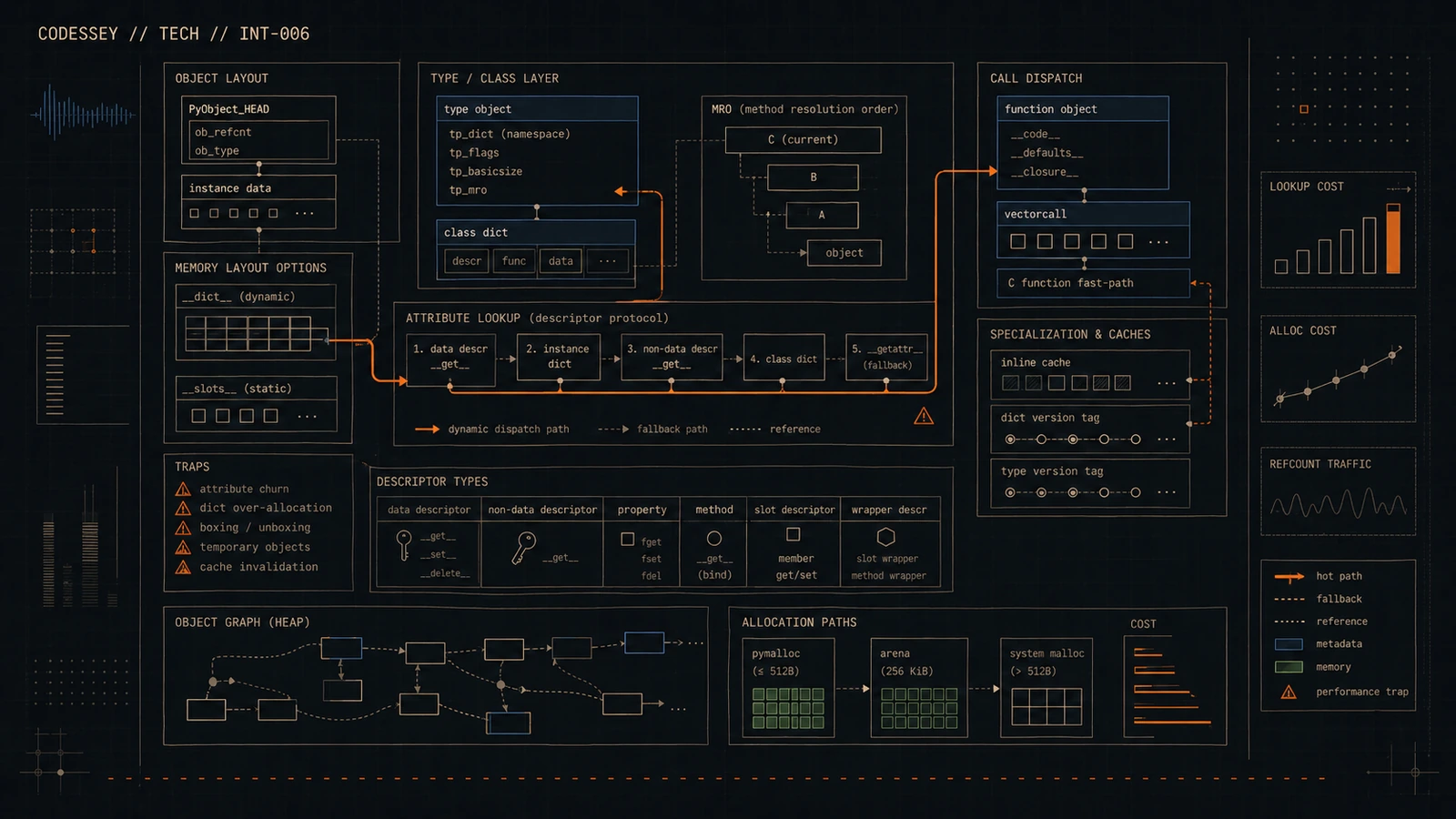
Coda: That’s the structure that holds everything that is shared by all possible instances of that class. It’s usually accessible through the class’s dict, and it holds all the methods and class variables. Then when I create an instance, use, I, Stanley Grylls, user, that specific instance gets its own private namespace. The instance namespace, yes.
Odyssey: This is implemented by that instance’s dict attribute. This dictionary is totally unique to it, and it’s where all its personal attributes will be stored.
Coda: Okay. Here’s the moment of truth. The lookup. When I write u.species, what is the exact order of operations Python follows to find that human string?
Odyssey: It follows a very strict, very important order. First, and always first, it checks the instance’s private dictionary, u.dict. So if I had set u.species equals cyborg, it would find that first and stop?
Coda: Immediately. It would return cyborg, and the search will be over. But in our case, it’s not there. So, step two. It looks at the class. It looks in the class’s namespace. It finds species there and returns human. If it wasn’t there, it would then continue searching up the inheritance chain of parent classes. And that search up the chain isn’t random. It follows something called a C3 method resolution order, or MRO.
Odyssey: Exactly. We can’t just throw that term out there. The MRO is the deterministic ordered list of classes that Python will search. It’s calculated with a clever algorithm called C3 linearization. What does that guarantee?
Coda: It guarantees that even in really complex multiple inheritance situations, the search order is predictable and consistent. It makes sure that a class’s local methods are always checked before its parents, and that the order of the parent classes is respected. It prevents chaos.
Odyssey: Okay, let’s look at dynamic assignment. I have my instance U. I now write U.Role admin. Where is that role attribute stored?
Coda: It is stored exclusively in the instance dictionary, U not adequate.
Odyssey: This is a dynamic update to that one specific instance’s namespace. So, if I had another instance, U2 article, it would not have a role attribute. Correct. U2.Role would raise an attribute error because that assignment only touched use private dictionary. They are completely separate. Now, this flexibility is great, but all these dictionaries must use up a lot of memory, right, if I have millions of simple objects. They absolutely do. Each instance carrying around its own dict hash table is flexible, but it’s not memory efficient.
Coda: And that’s where a crucial performance feature comes in, slots.
Odyssey: Right.
Coda: This is where you can optimize. Slots is a special class attribute where you explicitly tell Python, do not create a dict for instances of this class. Instead, you give it a fixed list of the only attributes an instance will ever have. For example, slots, name, I’d role.
Odyssey: Exactly. When you do that, Python allocates space for those attributes more directly, often within the instance’s main memory block, more like a C struct. You lose the dict and you save a significant amount of memory.
Coda: That’s the trade-off. Performance for flexibility. You can no longer add new arbitrary attributes to your instances. If you try to set an attribute that’s not in slots, you get an attribute error. It’s a key optimization for when you’re creating huge numbers of small objects.
Odyssey: Okay, last thing in this section. Let’s revisit callable types and specifically how methods work. When I define a function inside a class, it’s just a plain function object, right?
Coda: It is, until you access it through an instance. So when I say u.getspecies. Python performs a little magic on the fly. It takes that plain function and wraps it up into what’s called a bound instance method object. And what does that bound method contain?
Odyssey: It bundles together three things. The original function, the class it came from, and crucially, the instance it was accessed from, u, which it stores as self. And the genius of that is when I actually call it u.getspecies, Python automatically sticks that stored instance u in as the first argument. The argument we all call self by convention. It happens automatically.
Coda: That’s what binding is. If you accessed it from the class directly, user.getspecies, you’d just get the unbound function, and you’d have to pass the instance in manually. It’s a really elegant system.
Odyssey: Okay, we’ve seen how objects are born and how we find them. Now we need to talk about how they die.
Coda: This is memory management and the garbage collection contract. And this contract is simple, but it’s probably the one most violated by new programmers.
Odyssey: Yeah. Python handles memory for you. You never explicitly destroy an object. The contract says that when an object becomes unreachable. Meaning nothing points to it anymore. It may be garbage collected.
Coda: The key word there is may. The language specification explicitly says that implementations can postpone garbage collection or even skip it entirely. The timing of reclamation is not guaranteed. That lack of a guarantee is the single most important lesson here. You have no control over when it happens.
Odyssey: Yeah, exactly. And because of that, different Python interpreters use different strategies. Let’s start with CPython, the one everyone uses. CPython uses reference counting. Primarily, yes. Every single object has a tiny counter inside it. Every time a new name points to it, the count goes up by one. Every time a reference is removed, it goes down by one. And when that counter hits zero. The object is destroyed.
Coda: Yeah. Immediately. Instantly.
Odyssey: This is what makes CPython’s memory management feel so predictable and deterministic. But it has a major weakness. It has one Achilles heel. Reference cycles. Imagine object A has a reference to object B, and object B has a reference back to object A.
Coda: So their reference counts are at least one. There’ll always be at least one. Even if the rest of your program completely forgets about both of them, they’re keeping each other alive. They become unreachable.
Odyssey: But their reference counts never hit zero. They leak memory. So CPython has a backup plan for this.
Coda: It does. It has a separate delayed cycle detector. It’s a garbage collector that periodically scans for these isolated islands of objects pointing to each other and cleans them up. But, and this is the catch, you have no idea when that cycle detector is going to run.
Odyssey: So the cleanup is non-deterministic. Now let’s contrast that with interpreters like PyPy, which use a different strategy entirely.
Coda: Right. PyPy uses what’s called a tracing garbage collector.
Odyssey: It doesn’t use reference counts as its main strategy. How does it work?
Coda: Periodically, it pauses and does a trace. It starts from the roots of the program, global variables, the current function called stack, and it follows every reference, marking every object it can reach as live. And then?
Odyssey: Then it just sweeps away everything that wasn’t marked.
Coda: So what’s the practical difference for a programmer?
Odyssey: It’s huge. In a tracing GC system like PyPy, an object can become unreachable and still stick around in memory for a long time, until the next GC trace happens to run. So if your code assumes that as soon as a variable goes out of scope, the object it held is gone. That code will work fine on CPython for non-cyclical data, but it will break on PyPy. The object might not be collected for seconds or even minutes.
Coda: Yes, the timing is completely unknown. And this non-determinism, which is a core part of the Python spec, leads to the single most important rule for managing external resources. Yes, because you can’t rely on when the GC runs. You must never rely on it to clean up finite external resources. We’re talking about things like open files, network sockets, database connections. Box, graphics windows, anything where the operating system has a limited number of them available.
Odyssey: If you wait for the GC to close your files, you will hit the system’s too many open files limit, and your program will crash. So you need an explicit way to release them, a close method. You must have one, and you must call it. This brings us to the most dangerous tool in the toolbox.
Coda: Yeah. The Dell method, the finalizer. Why is relying on Dell for cleanup so incredibly risky?
Odyssey: It seems so tempting, right?
Coda: Dell gets called right before an object is destroyed. It feels like a C++ destructor. But it is filled with traps. Give us a specific failure case.
Odyssey: Okay, imagine an object that opens a file, and it’s in it. You put the file.close. Call in, it’s Dell. Now, what happens if that object becomes part of a reference cycle?
Coda: The reference count never hits zero. The object never gets destroyed by the main mechanism.
Odyssey: Which means Dell is never called. The cycle detector might eventually find it, but it might not. The file handle stays open, potentially leaking resources or locking the file until your entire program shuts down. And what if something goes wrong inside the Dell method itself?
Coda: What if it raises an exception?
Odyssey: This is the other huge trap. If an exception happens inside the Dell, Python just silences it. It prints a little warning to the error stream and move on. The program doesn’t crash.
Coda: Which makes debugging a nightmare. The very thing that was supposed to clean up your resource failed, and you barely even get a notification about it. It’s awful for debugging.
Odyssey: Yeah. So we need something better. We need a solution that is tied to program flow, not to the unpredictable timing of the garbage collector. And the Pythonic solution for that is the context manager. The with statement and the context manager protocol.
Coda: It is the only reliable way to manage resources deterministically. So explain how the protocol, specifically the exit method, guarantees cleanup. An object that wants to be a context manager needs two methods. First, enter, which runs when you enter the with block. It sets up the resource, opens the file, acquires the lock, and returns it. And then the magic part. Exit. This method is guaranteed to be called the moment program execution leaves the with block.
Odyssey: It doesn’t matter if it finished normally, or if there was a return, or even if an exception was raised. As it will be called.
Coda: And that’s where you put your cleanup code. Your file.close. Or lock.release.
Odyssey: Precisely. It guarantees the cleanup happens exactly when you need it to, based on the structure of your code, completely bypassing the fragile and unpredictable nature of the GC.
Coda: So the final non-negotiable rule for your junior engineers is, if you are managing any external resource, you must wrap it in a context manager. You should avoid del-day for any cleanup that is critical to your program’s correctness.
Odyssey: Absolutely. It’s just not safe to rely on it. This has been an incredibly deep dive into the absolute bedrock of Python. Every single thing we’ve talked about today connects directly to writing better, faster, and less buggy code.
Coda: Right. So let’s summarize the key takeaways for your team. First, master the object triad. Identity, type, and value. You have to know which of these changes when you perform an operation.
Odyssey: That’s the key to understanding performance. Second, never ever confuses and dealing. Uses for identity, for value. And don’t write code that relies on implementation details like integer caching. It will break. Third, internalize the consequences of mutability and aliasing. When you create a list of lists, be explicit about making new objects. And remember that namespaces are just dictionaries that define a strict lookup order. Instance first, then up the class MRO. And finally, the big one.
Coda: Determinism is not guaranteed. Object destruction timing is a mystery. For any external resource, forget Dell exists and use the with statement every time. Now, you may have noticed a pattern. We kept talking about these special methods. EQ, I add, dict, enter, exit.
Odyssey: Right. We’ve established that when you write a plus B, Python isn’t guessing. It’s looking for a specific method on an A’s type to call.
Coda: Exactly.
Odyssey: Which means if you want to write your own custom object, let’s say a vector class, and you want it to behave like a native type. You want to be able to add two vectors together with the plus sign or get its length with len. You have to hook into this system.
Coda: Yeah. The big question is, how does Python know which method to call for which operator?
Odyssey: That is the secret language of the interpreter. It’s a system governed by protocols and special methods, those Dunder methods. And understanding that system is the key to writing custom types that feel like they’re a built-in part of the language.
Coda: It is the ultimate key to writing truly Pythonic code. That sounds like the perfect next step. Join us next time for session two, where we unlock the power of Dunder methods and make your own objects integrate perfectly into the Python ecosystem.